
https://github.com/boostcampaitech7/level2-nlp-datacentric-nlp-04
GitHub - boostcampaitech7/level2-nlp-datacentric-nlp-04: level2-nlp-datacentric-nlp-04 created by GitHub Classroom
level2-nlp-datacentric-nlp-04 created by GitHub Classroom - boostcampaitech7/level2-nlp-datacentric-nlp-04
github.com
1. 프로젝트 개요
자연어에서 독해 및 분석 과정을 거쳐 주어진 태스크를 수행하기 위해서는 자연어의 주제에 대한 이해가 필수적이다. KLUE-Topic Classification benchmark는 뉴스의 헤드라인을 통해 그 뉴스가 어떤 topic을 갖는지를 분류해 내는 task로, 각 자연어 데이터에서 생활문화, 스포츠, 세계, 정치, 경제, IT과학, 사회 등 다양한 주제 중 하나로 라벨링한다. 본 프로젝트는 Data-Centric의 목적에 맞게 주어진 데이터셋을 바탕으로 베이스라인 모델의 수정 없이 오로지 데이터의 수정으로만 성능 향상을 이끌어내야 한다.
학습 데이터셋은 총 2800개로 구성되어 있으며, Normal Dataset 200개, Labeling Error Dataset 1000개, Random Noise Dataset 1600개로 이루어져있다. 프로젝트 진행의 편의를 위해 대회 제공 데이터를 1_base_2800로 명명했다.
2. 프로젝트 진행과정
2.1. 프리뷰
2.1.1. 베이스라인 temple화
기존 베이스라인 코드는 notebook 형태로 배포되었다. 그렇기 하나의 파이썬 파일로 정리한 뒤, 각각의 함수로 리팩토링 과정이 필요하다고 판단하였다. 데이터, 모델, 평가 metric, 학습으로 나누어 리팩토링을 진행하였다. 그리고 파일을 실행하여 학습부터 추론까지 모두 진행되도록 하였다.
또한 원활한 실험을 위하여 필요한 parameter를 config를 통해 바깥으로 빼내는 작업을 하였다. 이전에 피드백을 반영하기 위하여 최대한 하드 코딩이 이루어지지 않도록 하였고, 경로도 모두 os.path.join 함수를 사용하여 반영하였다.
2.1.2. 데이터 명명 규칙
프로젝트는 Data Centric 접근 방식을 따르기 때문에, 실험 과정에서 많은 데이터가 생성될 것이라 예상했다. 따라서 일관된 규칙을 바탕으로 데이터셋의 이름을 명명한다. 데이터셋은 “번호_데이터셋 유형_데이터셋 길이”로 구성된다. 데이터셋 길이가 별도로 표시되어있지않다면, 2800이라고 가정한다. ex) 1_base_2800 or 1_base 데이터셋 유형은 아래와 같다.
| 데이터셋 유형 | 설명 |
| base | 대회에서 제공된 원본 데이터셋 (Baseline) |
| noise_detect | 노이즈/비노이즈 구분 칼럼(is_noise)을 추가한 데이터 |
| relabel | 잘못된 target 값을 수정한 데이터 |
| denoise | 특수문자 제거 또는 노이즈 필터링을 적용한 데이터 |
| augmentation | 데이터 증강을 적용한 데이터 |
2.1.3. 고정된 실험환경
이번 프로젝트는 Data-Centric 접근 방식을 따르기 때문에, 모델 수정 없이 데이터 수정만으로 성능 향상을 이루어내야한다. 대회의 규칙에 따라 “klue/bert-base” 모델을 사용하였으며, epoch/lr_seheduler_type은 변경하지 않았다. 변경 가능한 베이스라인 코드는 batch size, max sequence length, train&valid split 비율, learning rate가 있다.
train batch size 실험에서 사용한 데이터는 1_base이며, train batch size를 제외하고 모든 실험환경이 동일하다.
| train batch size | eval loss | eval f1 / accuracy |
| 16 | 1.58138 | 0.42463 / 0.42857 |
| 32 | 1.6909 | 0.4198 / 0.41786 |
| 64 | 1.8255 | 0.3598 / 0.3571 |
train batch size는 더 빠르고 안정적인 학습을 위한 32로, eval batch size는 평가 시간을 단축하기 위해 1024으로 설정하였다.
train&valid split 비율 실험에서 사용한 데이터는 1_base이며, train&valid split 비율을 제외하고 모든 실험환경이 동일하다.
| train & valid split | train loss | eval f1 | public f1 / accuracy |
| 0.1 | 1.6118 | 0.42439 | 0.6599 / 0.6703 |
| 0.2 | 1.7026 | 0.34838 | 0.4915 / 0.5258 |
| 0.3 | 1.7225 | 0.38234 |
train&valid split 비율은 9:1일 때 성능이 가장 좋은 것을 확인하고 0.1로 설정하였다.
위 실험을 바탕으로 별도의 언급이 없다면 대부분의 테스트 결과 파일 생성 실험은 동일한 환경에서 진행되었으며, 베이스라인의 하이퍼파라미터는 다음과 같다.
| train batch size | 32 | train valid split | 0.1 |
| eval batch size | 5000 | SEED | 456 |
| learning rating | 2e-05 | max length | 30 |
| epoch | 2 | lr_seheduler_type | linear |
2.1.4. LLM 모델 선정
이번 프로젝트에서 LLM을 사용하여 데이터 증강과 노이즈를 포함한 데이터의 노이즈 제거 및 원본 문장 복원 실험을 진행하였다. 사용하는 prompt마다 다른 결과를 출력하기 때문에 모든 실험마다 각기 다른 프롬포트를 사용하여 실험하였다.
별도의 표시가 없다면 LLM에 사용된 모델은 EXAONE-3.0-7.8B-Instruct이다. 이 모델은 KoMT 벤치마크에서 높은 점수를 기록하였고 한국어에 최적화된 구조를 가지고 있어, 한국어 텍스트의 작업에서 보다 정확하고 자연스러운 결과를 얻을 수 있을 것이라 생각해 선정하였다.
2.2. 노이즈 비노이즈 데이터 구분
대회의 특성상, 각 데이터 유형에 따라 적용해야 하는 실험 방향이 명확하다. 노이즈가 포함된 데이터에 대해서는 노이즈 제거가 필요하고 비노이즈 데이터 중 잘못된 타겟 값이 포함된 경우에는 이를 수정해야한다. 따라서 실험의 첫 단계로, 노이즈 데이터와 비노이즈 데이터를 구분하는 작업을 우선적으로 진행하였다.
2.2.1. 아스키코드 기반
우선 아스키코드 기반으로 노이즈가 들어간 만큼 아스키코드로 변환하여 노이즈 유무를 구분할 수 있는 형식식이나 군집이 있는지 확인하였다. 해당 과정은 각 행들의 text 각각을 아스키코드로 변환하고 배열로 처리하여 별도의 column을 만드는 방법으로 진행되었다.

이후 해당 아스키코드 배열 칼럼의 평균 분포를 확인하거나, 한글 음절 범위 및 한자범위의 아스키코드를 제외시킨 아스키코드 배열 칼럼의 평균 분포를 확인하며 노이즈 유무를 확인할 수 있는지 접근하여 보았다.
하지만 이러한 간단한 방법론으로는 ‘%’, ‘...’, ‘↑’, ‘↓’와 같은 특수문자가 있는 비노이즈 문장을 오판별하는 문제가 있었다. 그러한 특수문자 아스키코드까지 비노이즈로 처리하기에는 다른 노이즈문장을 비노이즈로 분류하는 등의 문제가 있었다.
따라서 아스키코드 기반으로 노이즈를 확인하는 방법론은 1000개 노이즈 데이터를 정확히 분류하기에 한계점이 명확하였다.
2.2.2. 특수문자 비율별 시각화
문장 내에서 전체 문자의 길이 대비 특수문자의 개수를 통해 노이즈 데이터를 분류해보고, 눈으로 직접 확인해보았다.

노이즈 비율이 높을수록 문장의 의미를 파악하기 어려운 경향성이 있긴 했지만, 비율이 비교적 높음에도 불구하고 정상적인 텍스트이거나, 복구의 여지가 보이는 데이터들도 있었다.


본 프로젝트에 노이즈에서 노이즈는 특수문자 형태만으로 존재하는 것이 아니었기 때문에, 노이즈가 끼어있는 모든 문장의 패턴을 잡아내기에는 부족한 방법이었다고 판단하였다.
디노이징과 필터링을 위한 적절한 전처리와, 몇 가지의 Rule을 통해 최적의 교집합을 찾아내는 것에 집중해봤으면 좋았을텐데 하는 아쉬움이 있었다.
2.2.3. 특수문자와 알파벳을 활용한 구분
2.2.3~2.2.5의 Confusion Matrix는 is_noise 칼럼을 기준으로 작성되었으며, 여기서 1은 노이즈가 포함된 데이터를 0은 노이즈가 포함되지 않은 데이터를 의미한다. 별도의 명시하지 않은 경우, Confusion Matrix는 비율을 기준으로 계산되었다.
특수문자와 알파벳을 활용해서 노이즈가 포함된 데이터와 노이즈가 포함되지 않은 데이터로 구분하는 실험을 진행하였다. 실험 진행과정은 다음과 같다.
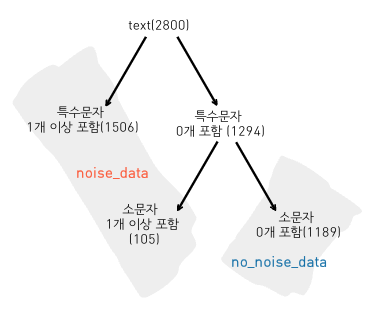
뉴스 기사 제목을 분석하여, 텍스트 내에 잘 사용되지 않는 특수 문자의 개수를 확인했다. 특수 문자가 0개인 경우는 노이즈가 포함되지 않은 데이터일 가능성이 높다고 가정했다. 이를 바탕으로 1294개의 데이터 중 텍스트 내에 소문자가 포함되지 않은 경우를 노이즈가 포함되지 않은 데이터로 간주하였는데, 이는 대부분의 기사 제목에서 영어가 대문자로 작성되기 때문이다. 단, IoT나 단위를 나타내는 "m"과 같이 예외적인 단어가 포함된 경우, 노이즈가 없는 데이터라도 노이즈로 분류되는 경우가 발생할 수 있다. 이러한 기준에 따라, 전체 데이터 중 노이즈가 포함된 데이터는 1611개, 노이즈가 포함되지 않은 데이터는 1189개로 구분되었다. 결과를 Confusion Matrix로 나타내면 아래와 같다.
실험 후 생성된 데이터 이름을 1_noise_detect라고 한다.

2.2.4. 패턴 기반의 구분
노이즈를 구분하는데 있어서 가장 중요하게 생각했던 것은 노이즈가 아닌데 노이즈로 구분되는 것을 최소화하는 것이다. 문장에서 특수문자 비율로 측정하는 것은 한글이 영어나 숫자로 대체되는 경우를 탐지하지 못하고, 영어나 숫자를 추가했을 때는 정상 문장도 노이즈로 탐지하는 등의 문제가 있었다. 그리고 앞선 방법들은 문장 단위로 판단하기 때문에 특정 단어 한 두개만 오염된 경우를 잘 탐지하지 못했다. 그래서 문장 단위가 아닌 단어 단위에서 패턴 기반의 노이즈 탐지 방식을 고안하게 되었다. KoNLPy 패키지의 Okt 형태소 분석기를 활용하여 각 단어들을 형태소 단위로 쪼갠 뒤 데이터를 살펴보며 현실의 문장에서 존재하지 않는 패턴을 추릴 수 있었다.
첫 번째 패턴인 혼합 단어 패턴은 한 단어에 “영어+숫자+한글+특수문자”처럼 여러 문자가 하나 이상씩 들어가는 경우와 “영어+한글+영어”, “특수문자 + 한글 +특수문자”와 같이 한 단어에 영어나 특수문자가 두번 이상 들어가는 경우를 탐지했다. “숫자+한글+숫자” 패턴은 “1대1”, “6대4”와 같은 표현을 현실에서 많이 사용하기 때문에 제외했다. 혼합 단어 패턴은 “갤럭시S8+”처럼 매우 특이한 케이스의 제품명을 제외하면 현실의 단어에서 존재하지 않았다.
두 번째 패턴은 샌드위치 패턴으로, 영어나 특수문자가 단어 내 한번씩만 나타나지만 한글 사이에 끼어있는 경우로 “한글+영어/특수문자+한글” 패턴이다. 그러나 실제 현실에 사용되는 표현 중에 “충북·충남” 처럼 가운뎃점은 단어를 나열할 때 쓰이고, “1월~3월”처럼 물결은 사이 기간을 나타낼 때, 부등호와 화살표 문자는 두 단어 사이의 관계를 표시할 때 쓰인다. 이렇게 의미있고 자주 사용하는 특수문자는 패턴에서 제외하고 의미 없는 특수문자만 포함시켰다. 샌드위치 패턴은 “우리WON뱅크” 같은 서비스명을 제외하면 존재하지 않았다.
세 번째 패턴은 연속 특수문자 패턴이다. 실제로 특수문자가 연속으로 사용되는 경우는 “...”같이 마침표를 연속으로 사용하여 말줄임을 나타내거나, “%↑”와 같이 퍼센트와 화살표를 같이 사용하여 상승/하락 폭을 나타내는 경우를 제외하고는 거의 없었다. 이렇게 총 1257개의 노이즈 데이터와 3개의 오탐지 데이터(비노이즈 데이터)를 탐지했다.
전체 노이즈 데이터 1400개 중 나머지 143개를 탐지하기 위해 다른 팀원들이 사용했던 방식을 참고했다. 문장 내에서 특수문자 비율과 특수문자와 영어 소문자의 비율을 이용하는 것인데, 여기에 형태소 분석기를 사용하는 방식을 더해 문자 단위와 형태소 단위의 비율 측정을 동시에 활용하였다. 앞서 충분히 많은 노이즈 데이터를 탐지하였기 때문에, 비율 기반의 방식에서 임계값을 상당히 작은 값으로 엄격하게 탐지할 수 있었고, 총 137개의 노이즈와 9개의 비 노이즈 데이터를 탐지하였다. (오탐지 여부는 직접 눈으로 확인하였기 때문에 한 두개 정도 오차가 발생할 수 있으나 팀원들의 도움으로 검수 받았기 때문에 신뢰할 수 있다. 또한 대회 규정상 직접 데이터를 수정하는 것은 불가능하기 때문에, 오탐지 데이터도 노이즈에 포함시켜 사용하였다.) 이러한 기준에 따라, 전체 데이터 중 노이즈가 포함된 데이터는 1606개(실제 노이즈 1594개 + 비노이즈 12개), 노이즈가 포함되지 않은 데이터는 1194개(실제 비노이즈 1188개 + 노이즈 6개)로 구분했다. 결과를 Confusion Matrix로 나타내면 아래와 같다.
실험 후 생성된 데이터 이름을 2_noise_detect라고 한다.

2.2.5. 노이즈 비노이즈 구분 정확도 분석
FP와 FN를 줄이기 위해 1_noise_detect와 2_noise_detect 데이터셋의 is_noise 칼럼에 대해 cleanlab을 적용해서 실험을 진행하였다. Cleanlab에 대한 자세한 설명은 2.3.1.Cleanlab 섹션에서 확인할 수 있다.
| 새로운 데이터셋 | 사용한 데이터셋 | 변경된 target 수 |
| 3_noise_detect | 1_noise_detect | 11 |
| 4_noise_detect | 2_noise_detect | 6 |
11개, 6개의 target이 변경되었으며, 모두 올바르게 수정되었다. 실험 후 생성된 데이터 이름을 3_noise_detect와 4_noise_detect라고 한다.
4_noise_detect 데이터셋에 대해 다시 한번 is_noise 칼럼에 cleanlab을 적용하였다.
| 사용한 데이터셋 | 변경된 target 수 | |
| 4_noise_detect | 5_noise_detect | 6 |
총 6개의 target이 변경되었으며 그중 1개의 데이터에 대해서 target이 잘못 수정되었다. 실험 후 생성된 데이터 이름을 5_noise_detect라고 한다.
추가적인 cleanlab 적용은 중단하고, 실험을 통해 생성된 5개의 noise_detect 데이터셋에 대해서 성능을 비교해보았다. 위 실험의 결과를 Confusion Matrix로 나타내면 아래와 같다.

Confusion Matrix를 바탕으로 분류 성능 지표인 accuracy, precision, recall, f1을 사용해서 성능을 평가하였다. 4개의 평가지표 모두에서 5_noise_detect의 성능이 가장 높은 것을 확인할 수 있다.
| 1_noise_detect | 2_noise_detect | 3_noise_detect | 4_noise_detect | 5_noise_detect | |
| accuracy | 0.98850046 | 0.99229961 | 0.99229458 | 0.99437994 | 0.99695125 |
| precision | 0.99075878 | 0.99328644 | 0.99328644 | 0.99498383 | 0.998265421 |
| recall | 0.98620193 | 0.99129983 | 0.99128991 | 0.99376994 | 0.995639956 |
| f1 | 0.98847511 | 0.99229214 | 0.99228717 | 0.99437651 | 0.99695096 |
5_noise_detect 데이터셋의 Confusion Matrix를 데이터의 개수를 기준으로 계산한 결과는 아래와 같다.

2.3. relabeling
데이터셋의 노이즈가 포함되지 않은 데이터는 1200개이고, 이중 1000개는 잘못된 target을 가지고 있다. 따라서, 잘못된 target 값을 relabeling해야한다.
2.3.1. Cleanlab
Cleanlab은 Confident Learning을 기반으로 모델의 예측 확률과 주어진 레이블 간의 불일치를 탐지하여 레이블 오류를 식별한다. Stratified K-Fold 교차 검증을 사용하여 데이터의 레이블 오류를 탐지하는데, 이는 데이터셋을 K개의 폴드로 나눌 때 각 폴드에 모든 클래스의 샘플이 균형있게 포함되도록 하는 기법이다. 이를 통해 클래스 분포의 균형을 유지하여 편향을 줄이고, 모델의 일반화 성능을 더 정확하게 평가할 수 있다. 별도의 명시가 없다면 학습을 진행할 때는 베이스라인의 모델과 동일하게 klue/bert-base 모델을 사용하였다.
실험 결과 표의 칼럼 설명은 아래와 같다.
| column name | 설명 |
| number of label issues found | Cleanlab 결과 발견된 Label Issue 개수 |
| number of label issues found(noise) | 발견된 Label Issue 중 Noise Data인 경우 |
| base target ≠ changed target | Base 데이터셋과 최종 변경된 데이터셋의 Target 값이 다른 경우 |
실험1. 모든 데이터에 대해서 target을 relaebl하는 Cleanlab 진행.
1_base 데이터셋을 기반으로 Cleanlab을 적용하여 새로운 데이터셋을 생성하고, 생성된 데이터셋에 다시 Cleanlab을 적용하는 연속적인 실험을 진행하였다.
| 사용한 데이터셋 | number of label issues found |
public f1 / accuracy | |
| 1_base | 0.6599 / 0.6703 | ||
| 1_relabel | 1_base | 691 | 0.6263 / 0.6387 |
| 2_relabel | 1_relabel | 330 | 0.7371 / 0.7381 |
| 3_relabel | 2_relabel | 185 | 0.7526 / 0.7537 |
| 4_relabel | 3_relabel | 100 | 0.7607 / 0.7610 |
| 5_relabel | 4_relabel | 58 | 0.7589 / 0.7585 |
리라벨링 초기 단계에서는 데이터의 품질이 개선되며, 잘못된 레이블이 수정됨에 따라 모델의 성능이 향상되어 f1 score와 accuracy가 증가하는 것을 볼 수 있다. 여러 번 리라벨링을 할 수록 f1 score와 accuracy가 감소하는데, 이는 특정 데이터에 과적합되었을 가능성이 있다.
실험2. 노이즈 데이터에 대해서만 target을 relabel하는 Cleanlab 진행.
노이즈가 포함된 데이터는 잘못된 타겟 값을 가지는 것이 아니기 때문에 relabelling 후 is_noise == 1인 데이터에서 변경된 타겟 값이 있을 경우 변경 전 타겟 값을 유지하였다.
실험2-1. 특수문자를 제거 후 Cleanlab 적용
1_noise_detect 데이터셋을 사용해서 뉴스기사 제목에서 자주 사용하지 않는 특수문자를 모든 text에서 제거한 후, Cleanlab을 적용하였다. base target ≠ changed target의 개수가 1000에 가까워질 때 실험을 종료하였는데, 이는 잘못된 타겟 값이 약 1000개라는 사전 정보에 기반한다.
| 사용한 데이터셋 | number of label issues found |
number of label issues found(noise) |
base target ≠ changed target | public f1 / accuracy | |
| 1_noise_detect | 0.6599/ 0.6703 | ||||
| cleaned_1 | 1_noise_detect | 829 | 367 | 402 | |
| 7_relabel | cleaned_1 | 667 | 328 | 777 | 0.7824 / 0.7859 |
| 6_relabel | 7_relabel | 316 | 212 | 1070 | 0.7952 / 0.7987 |
1_noise_detect 데이터셋에서 Cleanlab을 적용하여 1070개의 타겟 값을 수정한 결과, 새로운 데이터셋 6_relabel이 생성되었다. 이 데이터셋을 사용한 모델의 성능이 다음과 같이 약 0.14만큼 향상되었다.
실험2-2. 특수문자를 제거하지 않고 Cleanlab 적용
1_noise_detect 데이터셋을 사용하되 특수문자를 제거하지 않고, 원본 데이터셋에 Cleanlab을 적용하였다.
| 사용한 데이터셋 | number of label issues found |
number of label issues found(noise) |
base target ≠ changed target | public f1 / accuracy | |
| 1_noise_detect | 0.6599/ 0.6703 | ||||
| clean1 | 1_noise_detect | 756 | 336 | 420 | |
| clean2 | clean1 | 722 | 324 | 779 | |
| 8_relabel | clean2 | 331 | 223 | 868 | 0.7847 / 0.7882 |
| 9_relabel | 8_relabel | 262 | 217 | 901 | 0.8083 / 0.8116 |
| 10_relabel | 9_relabel | 243 | 211 | 924 | 0.7678 / 0.7692 |
1_noise_detect 데이터셋에서 Cleanlab을 적용하여 901개의 타겟 값을 수정한 결과, 새로운 데이터셋 9_relabel이 생성되었다. 이 데이터셋을 사용한 모델의 성능이 다음과 같이 약 0.15만큼 향상되었다. 9_relabel의 성능이 10_relabel의 성능보다 높은 이유는 Cleanlab을 반복적으로 적용하면, Label Issue를 지나치게 탐지하게 되어 원래는 타겟 값이 올바른 데이터를 잘못된 데이터로 인식하고 수정할 가능성이 높아지기 때문이다.
| public f1 / accuracy | |
| 6_relabel | 0.7952 / 0.7987 |
| 9_relabel | 0.8083 / 0.8116 |
2.4.1 특수문자제거 섹션에서와 동일하게, 특수문자를 제거하지않고 Cleanlab을 진행한 9_relabel이 특수문자를 제거한 4_relabel보다 성능이 더 높은 것을 확인하였다.
| dataset | public f1 / accuracy |
| 4_relabel | 0.7607 / 0.7610 |
| 9_relabel | 0.8083 / 0.8116 |
모든 데이터에 대해 relabel을 한 4_relabel보다 relabelling 후 is_noise == 1인 데이터에서 변경된 타겟 값이 있을 경우 변경 전 타겟 값을 유지한 9_relabel의 성능이 더 높은 것을 확인하였다.
실험2-3. 5_noise_detect 데이터셋에 Cleanlab 적용하기
실험 2-1과 2-2는 1_noise_detect 데이터셋을 사용한 실험이다. 2.2.5. 노이즈 비노이즈 정확도 분석 섹션을 통해 노이즈와 비노이즈 데이터를 더 정확히 구분한 5_noise_detect 데이터셋을 생성하였다. 따라서 이 데이터를 활용해서 실험을 진행한다. 실험방법은 실험2-2와 동일하다.
| 사용한 데이터셋 | number of label issues found |
number of label issues found(noise) |
base target ≠ changed target | public f1 / accuracy | |
| 1_noise_detect | 0.6599/ 0.6703 | ||||
| clean1 | 1_noise_detect | 828 | 323 | 505 | |
| clean2 | clean1 | 309 | 212 | 899 | |
| clean3 | clean2 | 229 | 186 | 932 | |
| 20_relabel | clean3 | 222 | 191 | 948 | 0.8165 / 0.8138 |
5_noise_detect 데이터셋에서 Cleanlab을 적용하여 948개의 타겟 값을 수정한 결과, 새로운 데이터셋 20_relabel이 생성되었다.
| dataset | public f1 / accuracy |
| 20_relabel | 0.8165 / 0.8138 |
| 9_relabel | 0.8083 / 0.8116 |
노이즈와 비노이즈 데이터의 구분 정확도가 높은 5_noise_detect 데이터셋을 사용하여 Cleanlab을 적용한 결과 생성된 20_relabel 데이터셋의 성능이, 상대적으로 노이즈 탐지 정확도가 낮은 1_noise_detect 데이터셋을 사용하여 Cleanlab을 적용한 9_relabel 데이터셋의 성능보다 더 높았다. 이 실험을 통해 노이즈 탐지 정확도가 높을수록 Cleanlab의 Label Issue 수정 성능이 향상되고, 결과적으로 모델 성능도 개선된다는 것을 알 수 있었다.
실험3. Cleanlab을 활용해서 노이즈 데이터 삭제하기
실험3-1. Cleanlab을 활용해서 노이즈 데이터 삭제하기
몇 차례의 cleanlab을 진행했는데, noise_data의 라벨을 바꾼다는 것은 해당 데이터를 이해하지 못한다고 생각하였다. 따라서 임의의 횟수만큼 cleanlab을 진행하고(진행 방법은 실험2-3과 동일) relabelling 후 is_noise == 1인 데이터에서 변경된 타겟 값이 있을 경우 해당 데이터를 삭제하였다.
1_noise_detect 데이터셋에 대해서 3번의 cleanlab을 진행한 9_relabel 데이터셋을 사용하였다. (실험2-2참고)
| 사용한 데이터셋 | number of label issues found |
number of label issues found(noise) |
base target ≠ changed target | public f1 / accuracy | |
| 11_relabel_2583 | 9_relabel | 262 | 217 | 901 | 0.8022 / 0.8048 |
relabelling 후 is_noise == 1인 데이터에서 변경된 타겟 값이 있을 경우인 217개의 데이터를 모델이 이해하지 못한다고 판단하고 삭제하였다.
실험3-2. Cleanlab을 활용해서 노이즈 데이터를 삭제한 뒤 Cleanlab 활용하기
1_noise_detect 데이터셋에 대해서 1번의 cleanlab을 진행한 실험 2-2의 clean1 데이터셋을 사용하였다. relabelling 후 is_noise == 1인 데이터에서 타겟 값이 변경된 324개의 데이터를 모델이 이해하지 못한다고 판단하고 삭제하고 이 데이터셋을 drop_clean1_2476이라고 명명하였다. 이 데이터를 활용해서 실험2-3의 규칙과 동일하게 cleanlab을 실행하였다.
| 사용한 데이터셋 | number of label issues found |
number of label issues found(noise) |
base target ≠ changed target | public f1 / accuracy | |
| drop_clean1_2476 | clean1 | 722 | 324 | 779 | |
| 12_relabel_2476 | drop_clean1_2476 | 122 | 42 | 843 | 0.7972 / 0.7993 |
| 13_relabel_2476 | 12_relabel_2476 | 110 | 51 | 888 | 0.8054 / 0.8069 |
노이즈 데이터를 drop한 후 cleanlab을 적용한 결과인 13_relabel_2476의 성능이, drop만 진행한 경우보다 더 우수한 결과를 나타냈다.
| dataset | public f1 / accuracy |
| 9_relabel | 0.8083 / 0.8116 |
| 11_relabel_2583 | 0.8022 / 0.8048 |
| 13_relabel_2476 | 0.8054 / 0.8069 |
9_relabel 데이터셋은 노이즈 데이터를 Drop하지 않고, Cleanlab을 통해 relabeling을 진행한 데이터셋이다. 이 데이터셋의 성능은, 노이즈 데이터를 일부 Drop하고 Cleanlab을 적용한 11_relabel_2583과 13_relabel_2476보다 더 우수한 결과를 보였다. 결과를 통해 두가지에 대해 생각하게 되었다.
- 데이터의 수는 성능에 큰 영향을 미친다. 일부 데이터를 Drop하면, 데이터의 다양성이 감소하고 모델의 학습이 제한될 수 있다.
- 데이터의 품질뿐만 아니라 데이터의 양과 다양성도 Data-Centric 접근에서 중요한 요소임을 알게 되었다.
실험4. 노이즈 데이터 학습 및 비노이즈 데이터 검증을 통한 Cleanlab 적용
이번 실험에서는 학습 데이터로 노이즈 데이터(1602개)를 사용하고, 검증 데이터로는 비노이즈 데이터(1198개)만을 사용하여 Cleanlab을 적용했다. 이전 실험(1-3)에서는 2800개의 데이터셋을 k-fold로 나누어 진행했지만, 이번 실험에서는 노이즈와 비노이즈 데이터를 분리하여 학습 및 검증을 진행했다. 또한, 다양한 모델을 사용하여 성능을 비교하였다.
4-1. 모델 찾기
Hugging Face의 Fill-Mask 카테고리에서 한국어로 학습된 모델들을 찾았다. 이 카테고리에 속하는 모델들은 Masked Language Modeling (MLM) 기법을 기반으로 하며, 문장 내에서 특정 단어의 의미를 추론하거나 가장 적절한 단어를 예측할 때 사용된다. 이번 실험 데이터에는 노이즈가 많이 포함되어 있어, 이를 masked된 단어로 간주하고 MLM 모델을 선정하였다.
4-2. cleanlab 적용하기
학습에는 노이즈가 포함된 데이터, 검증에는 비노이즈 데이터를 사용했다. 모델의 성능은 발견된 Label Issue의 개수와 검증 데이터의 Eval F1 / Accuracy로 평가하였다.
모든 실험 환경은 동일하게 유지하고, 5_noise_detect 데이터를 사용했다.
| model | number of label issues found |
eval F1 / accuracy | |
| 22_relabel | klue/bert-base | 831 | 0.7488 / 0.75 |
| 23_relabel | kakaobank/kf-deberta-base | 923 | 0.7836 / 0.7893 |
| 24_relabel | vaiv/kobigbird-roberta-large | 958 | 0.7935 / 0.7964 |
24_relabel에서 Label Issue는 958개로 이는 다른 모델들보다 더 많은 Label Issue를 탐지하였다. 이는 vaiv/kobigbird-roberta-large 모델이 더 넓은 문맥을 이해하고, 더 정밀하게 Label Issue를 탐지했기 때문일 가능성이 크다고 생각했다. 모델의 성능은 발견된 Label Issue의 개수와도 밀접한 관련이 있으며, 더 많은 Label Issue를 탐지할수록 더 높은 F1 스코어를 보였다.
검증데이터 1198개 중 1000개와 가장 가까운 958개의 target을 변경한 24_relabel을 실험1-3 중 SOTA인 2O_relabel과 비교해보았다.
| dataset | base target ≠ changed target | public f1 / accuracy |
| 20_relabel | 948 | 0.8165 / 0.8138 |
| 24_relabel | 958 | 0.8081 / 0.8153 |
20_relabel이 Public F1 점수에서 더 높은 성능을 보였으나, 24_relabel이 Accuracy에서는 근소하게 더 높은 점수를 기록했다. 24_relabel에서는 Cleanlab 적용 과정에서 20_relabel보다 약간 더 많은 Label Issue가 탐지되고 수정되었다. 그러나, 이 과정에서 오탐을 할 가능성이 커지고 이로 인해 과적합이 발생했다고 생각한다. 따라서, 이 실험을 제외하고 모든 cleanlab 실험에서는 베이스라인 코드와 동일하게 klue/bert-base 모델을 사용하여 학습을 진행하였다.
2.3.2. Encoder 모델 기반
라벨 분류에 있어 encoder 기반 분류를 진행해보았다. 실험에 앞서 데이터의 노이즈 유무를 확인했으며, 노이즈가 있는 데이터는 라벨이 틀리지 않고, 반대로 라벨이 틀린 데이터는 노이즈가 없다는 특성을 파악하였다. 이를 기반으로 노이즈가 있는 데이터를 train set으로, 노이즈가 없는 데이터를 test set으로 활용하여 리라벨링을 시도하였다.
노이즈가 있는 데이터(라벨이 정확한 데이터)는 학습에 적합한 신뢰도 있는 데이터로 간주하고, 이 데이터를 활용해 라벨 분류 모델을 학습하였다. 그런 다음, 학습된 모델을 노이즈가 없는 데이터에 적용하여 잘못된 라벨을 교정하였다.
| base data | model | number of changed label |
| 2_noise_detect (pattern-based) |
snunlp/KR-ELECTRA | 1230 |
| 5_noise_detect (clean-lab based) |
snunlp/KR-ELECTRA | 1028 |
| 2_noise_detect (pattern-based) |
kakaobank/kf-deberta-base | 1335 |
| 5_noise_detect (clean-lab based) |
kakaobank/kf-deberta-base | 1002 |
해당 실험 진행결과 clean-lab을 기반으로 노이즈를 detect한 데이터를 kakaobank/kf-deberta-base 모델로 학습시켰을 때 1000개의 라벨이 바뀐 모습을 확인할 수 있었다. 원래 라벨 오류가 1000개이므로 해당 학습이 제일 relabeling 성능이 뛰어나다고 생각하여 추후 디노이징을 진행할 때 cleanlab_detect-bert_relabel라는 데이터 명으로 활용하였다.
relabel 실험의 한계는 바뀐 라벨의 갯수를 확실한 성능지표라고 할 수 없다는 것이다. 1000개의 데이터 라벨이 바뀌었다고 하더라도 실제로 라벨오류가 있는 데이터의 라벨이 바뀌지 않았고 라벨오류가 없는 데이터의 라벨이 바뀌는 등 recall과 precision의 성능이 낮을 수 있다. 하지만 추가적인 성능지표가 없어서 변경된 라벨 갯수를 차선의 성능지표로 활용하였다. 해당 부분은 추후 이 실험의 데이터를 활용한 또다른 실험이 진행될 때에도 충분히 고려되었다.
2.3.2. LLM
LLM 프롬프팅만으로 relabel은 어렵다고 생각하였다. label이 7개나 존재하였기에 각 label에 대한 few shot을 5개씩만 하여도 예시가 총 35개나 된다. 적게 주면 label에 대한 정보를 알기 어렵고, 너무 많이 주면 prompt가 너무 길어진다는 문제가 있었다. 그렇기에 직접 학습하여 relabeling을 하는 방법을 고안하였다.
어느 정도 denoise가 된 데이터를 바탕와 cleanlab으로 noise가 없음에도 label 변동이 없었던 데이터를 합쳐서 학습 데이터로 사용하였다. 1000개의 데이터를 테스트로 사용해볼 예정이었고, 이후 데이터 증강을 통해 성능을 올릴 생각이었다.
사용한 모델은 MLP-KTLim/llama-3-Korean-Bllossom-8B을 선택했다. 우선 결론부터 말하자면 이 아이디어는 결국 사용하지 못하였다. 대회 기간이 짧았던 점과 학습 과정에서 발생하는 cuda 오류를 해결하지 못하여 폐기하였다. cuda error: device-side assert triggered라는 오류에 부딪혔는데, 여러 방법들을 시도해보아도 결국 해당 오류의 원인을 정확히 찾아내지 못하였다. 추측되는 이유는 여럿 있었는데 라벨 수와 출력 단위 간의 불일치, batch_size의 문제, 환경 변수의 문제 등등이 있었다. 찾아보았을 때 나오는 문제들에 대하여 모두 확인을 해보았지만 이상은 없는 것으로 나왔다. 제대로 학습조차 못해보았던 방법이었기에 github에 업로드는 하지 않았다.
짧은 대회 기간이었기에 이 방법에 대해서는 조금 더 시간이 있었으면 하는 아쉬움이 있다.
2.4. denoising
데이터셋의 노이즈가 포함된 데이터는 1600개이다. 이 데이터에 대해서는 노이즈를 제거해야한다.
2.4.1. 특수문자제거
특수문자가 텍스트의 의미에 크게 영향을 주지 않는다고 판단하여, 텍스트 내 모든 특수문자를 공백으로 치환할 경우 성능이 1_base와 유사하거나 더 향상될 것이라는 가설을 세웠다.
사용한 데이터셋을 제외하고 모든 실험 환경을 동일하게 유지했다. 실험 후 생성된 데이터셋은 2_denoise로 명명하였다.
| dataset | eval f1 | public f1 / accuracy |
| 1_base | 0.42439 | 0.6599 / 0.6703 |
| 2_denoise | 0.416 | 0.5767 / 0.5955 |
실험 결과, 성능이 하락한 것을 확인할 수 있었다. 그 이유는 다음과 같다.
- 노이즈가 포함되지 않은 데이터에서도 특수문자가 제거되었기 때문에, 원래 의미를 유지하던 특수문자가 사라지면서 텍스트의 정보가 손실되었을 가능성이 크다.
- 특수문자를 공백으로 치환한 후, 텍스트의 형태가 달라지면서 토크나이징 결과도 변화하였고, 이는 모델의 성능에 부정적인 영향을 미쳤을 가능성이 크다.
2.4.2. 토크나이저
이번 실험에서는 T5 모델인 t5-large-korean를 사용하여 텍스트 데이터에서 노이즈를 제거하는 작업을 수행하였다. 이 모델은 국립 국어원 신문 말뭉치에서 50만 개의 문장을 기반으로 훈련되어 G2P(글자-음절 변환)된 데이터를 원본으로 되돌리는 역할을 한다.
| 원본 문장 | 변경된 문장 |
| 문/인 당2 4nS 민관2동7사위 /""X보 철거tt | 문인 당2 4ns 민관2동74위 X보 철거tt |
| 박항C 매직c베트남i축구_표팀K.?^# 쏟;*:d | 박항서 매직c베트남i축구표팀K 쏟d |
입력 텍스트를 배치 단위로 처리하여 디노이징을 시도하였으나, 8_denoising_2800, 9_denoising_2800 데이터 모두 base 데이터에 비해 성능이 기대에 미치지 못한 결과가 나타났다. 이에 대한 원인은 크게 두 가지일 것으로 예상한다.
| base | eval_f1/eval_loss | |
| 1_base | 0.4243/1.64683 | |
| 3_d_2800_hanzi_dictionary | 0.4271/ 1.6511 | |
| 8_denoising | 1_base | 0.3806/1.7063 |
| 9_denoising | 3_d_2800_hanzi_dictionary | 0.4183/1.6537 |
입력 데이터의 품질이 낮아 노이즈가 심각하게 포함되어 있는 경우, 모델이 효과적으로 학습하지 못할 수 있다. 원본 문장과 변경된 문장 예시에서 보듯, 일부 문장은 여전히 의미가 불명확하거나 잘못된 형식으로 남아 있다. 이러한 데이터는 모델이 올바른 출력을 생성하는 데 방해가 된다.
또한 배치 단위로 텍스트를 처리하는 방식은 메모리 효율성을 높이는 장점이 있지만, 각 배치 내의 데이터가 서로 다를 경우 일관된 성능을 보장하지 못할 수 있다. 특히, 배치 내에 노이즈가 심한 데이터가 포함될 경우, 전체적인 디노이징 성능에 부정적인 영향을 미칠 수 있다.
두 번째 실험에서는 노이즈가 없는 데이터로 훈련된 SentencePiece 모델은 노이즈가 있는 데이터를 처리하는 데 있어 성능을 발휘할 것으로 기대하였다. 노이즈가 없는 데이터를 사용하여 SentencePiece 모델을 훈련하였다. 이 과정에서 모든 텍스트 데이터를 임시 파일에 저장하고, 해당 파일을 기반으로 BPE(Byte Pair Encoding) 방식으로 모델을 학습시켰다.훈련된 SentencePiece 모델을 로드한 후, 노이즈가 있는 데이터를 토큰화하고 디토큰화하여 디노이징된 결과를 생성하였다.
| 원본 문장 | 변경된 문장 |
| 문/인 당2 4nS 민관2동7사위 /""X보 철거tt | 문/인 당2 4nS 민관2동74위 /""X보 철거tt |
| 박항C 매직c베트남i축구_표팀K.?^# 쏟;*:d | 박항서 매직c베트남i축구_표팀K.?^# 쏟;*:d |
본 실험에서는 SentencePiece 모델을 활용한 텍스트 디노이징 과정에서 주목할 만한 결과가 관찰되었다. 특히, 모델의 성능이 훈련 데이터의 특성과 입력 텍스트의 구조에 따라 상이한 결과를 보였다.
- 훈련 데이터에 포함된 단어의 복원 성능
- "박항C 매직c베트남i축구_표팀K.?^# 쏟;:d"
→ "박항서 매직c베트남i축구_표팀K.?^# 쏟;:d" - 훈련 데이터에 포함된 "박항서"와 같은 단어는 성공적으로 복원되었다. 이는 모델이 훈련 과정에서 해당 단어의 올바른 형태를 학습했음을 시사한다. 이는 노이즈 없는 데이터에 “아시안게임 목소리 높인 박항서 베트남이 일본 못 이길…” 이라는 올바른 문장이 있었기 때문이라고 보인다.
- 미등록 단어(OOV) 처리의 한계
노이즈가 없는 데이터가 약 1600 개로 토크나이저를 훈련할 충분한 수를 갖추지 못했기 때문에 토크나이저의 디노이징 성능이 떨어진 것으로 보인다. 노이즈가 없는 데이터를 증강하여 토크나이저를 충분히 훈련시켰다면 더 나은 디노이징 데이터를 생성할 수 있었으리라 생각한다.
2.4.3. 형태소분석기를 활용한 denoise
이번 실험의 주요 목적은 기사 제목의 특성을 고려하여 텍스트에서 중요한 정보를 추출하는 것이었다. 기사 제목은 주로 핵심 정보를 간결하게 전달하는 특성을 가지고 있어, 일반 명사, 고유명사, 동사, 형용사 등이 중요한 역할을 한다고 판단하였다. 이러한 품사들을 남겨 노이즈를 줄인다면 올바르게 라벨을 분리할 수 있을 것이라 생각했다.
두 가지의 형태소 분석기로 실험을 진행하였다. kkma 형태소 분석기는 품사를 추출할 수 있는 기능을 제공하여 실험에 활용하였다. Mecab 형태소 분석기는 일반 명사,고유명사 처리에 더 뛰어난 성능을 보인다는 평가가 있기 때문에 선택하였다. 특히 기사 제목에서 자주 등장하는 일반 명사, 고유명사를 정확히 식별하는 것이 중요하다고 판단하였다.
| 사용한 데이터 | 형태소 분석기 | 남긴 품사 | eval f1 | |
| 1_base | 0.4243 | |||
| 5_denoise | 1_base | kkma | 일반명사,고유명사 | 0.4142 |
| 10_denoise | 1_base | kkma | 일반명사,고유명사,수사,동사,형용사 | 0.4068 |
| 11_denoise | 1_base | Mecab | 일반명사,고유명사 | 0.3670 |
실험 결과, 예상했던 성능 향상이 나타나지 않았다. 선택한 품사만으로는 기사 제목의 전체적인 의미를 포착하기에 부족했을 수 있다.
2.4.4. BART 기반
대회에서 주어진 데이터에서 노이즈가 아닌 데이터에 노이즈를 주어 노이즈-원본 쌍의 데이터셋을 생성할 수 있었다. 이 데이터로 학습시킨 모델에 노이즈 데이터를 넣어 복구시키는 방법을 고안하여 실험에 들어갔다. 먼저 모델 선정 단계에서 BART를 선택했는데, BART(Bidirectional and Auto-Regressive Transformers)는 입력 텍스트 일부에 노이즈를 추가하여 이를 다시 원문으로 복구하는 autoencoder의 형태로 학습이 되는 모델이다. 따라서 노이즈 복구 작업에 적합하다고 생각했고, Huggingface에서 gogamza/kobart-base-v2와 hyunwoongko/kobart 모델을 사용하여 학습했다. 먼저 노이즈-원본 쌍의 데이터셋을 40% 오염시켜 만든 데이터로 학습했을 때는 문장을 거의 복구 하지 못했기 때문에 점점 노이즈 비율을 줄여가며 실험했다. 노이즈 비율을 20% 까지 줄였을 때 부터는 정상적으로 학습이 진행되었다. 훈련 데이터의 적합한 노이즈 비율을 찾은 뒤 훈련 및 실제 노이즈 데이터를 복구시켰을 때도 연속한 특수문자를 여러 번 생성하거나 한글을 제거하고 영어 단어로 복구하는 등의 문제가 발생했다. 따라서 노이즈 데이터에서 한글을 제외한 나머지 문자를 모두 제거한 뒤 복구를 시도했다. 예를 들어 "m 김정) 자주통일 새,?r열1나가야1보" 는 “김정 자주통일 새열나가야”로 전처리하고 사용하니 “김정은 자주통일 새 시대 열어가야 한다고 선언했다.”로 잘 복구되는 것을 확인할 수 있었다. 그러나 나머지 문장에서 단어가 반복적으로 등장하는 문제가 발견되어 Beam-Search에서 사용할 Beam의 개수를 늘리고 no_repeat_ngram_size를 줄이면서 점차 해결하였다. 그러나 "소리길 류동 곡" → “소리길길류동 곡 곡곡곡 곡성 곡창 곡선 곡반간 곡소” 와 같이 같은 단어가 연속으로 생성되며 원본 문장에 비해 길이가 길어지는 문제와 노이즈 비율이 높은 문장에 대해서는 문맥을 아예 이해하지 못하는 문제가 계속 발생했다. 따라서 노이즈 복구 과정에서 원본 문장의 길이 유지하는 것과 같은 단어를 연속해서 생성하지 않는 것을 다음 목표로 하였다. 우선 문장의 노이즈 비율별 노이즈 문장과 복구한 문장 쌍을 비교하며 제거할 비율을 설정하였다. 이후 원본 문장의 길이를 유지하면서 생성하는 방법을 고안하고 있었는데, 다른 팀원의 LLM 프롬프트 기반으로 노이즈를 복구하는 실험이 매우 성공적 이었고 내가 진행하는 실험에서 결과가 좋은 케이스들과 비교해도 훨씬 뛰어났다. 40GB 정도의 데이터를 학습한 파라미터 크기가 124M인 모델에 비해 8B 이상의 LLM 모델의 성능은 압도적이었다. 특별한 프롬프트를 쓰지 않았음에도 품질 차이가 크게 났으며 나의 실험이 성공적이여도 이정도 품질을 기대하지 못할거라는 생각에 실험을 여기서 마무리지었다. 노이즈 문장 복구 작업은 생각보다 큰 모델을 필요로 하는 작업임에도 너무 작은 모델로 실험을 진행한 것이 아쉬운 점으로 남았다.
2.4.5. LLM
EXAONE-3.0-7.8B-Instruct 모델을 사용하여 데이터의 노이즈를 제거하고 원본 문장을 유추하였다.
실험1.
노이즈가 있는 데이터는 라벨이 정확하기 때문에 LLM 기반으로 디노이징한 데이터를 통해서 증강을 하면 성능이 오를 것이라는 가설에서 시작하였다.
1-1. 데이터의 노이즈 제거와 원본 문장 유추
21_relabel의 노이즈가 있는 데이터를 LLM으로 디노이징하였다. 이 과정에서 모델은 노이즈를 제거하고 원본 문장 유추를 통해 더 정제된 데이터를 생성하였다.
1-2. 리라벨링
디노이징된 데이터를 바탕으로 27_relabel을 생성하였다. 이 단계에서 CleanLab을 사용하여 리라벨링을 수행하였다.
| 사용한 데이터셋 | eval f1 / loss | |
| 21_relabel | 0.7810 / 0.7819 | |
| 27_relabel | 21_relabel | 0.9034 / 0.3871 |
디노이징 결과, f1, loss 점수에서 모두 상승하였다.
실험2-1.
2-1. 데이터의 노이즈 제거와 원본 문장 복원
5_noise_detect 데이터셋의 is_noise == 1 (노이즈가 포함된) 데이터를 대상으로, LLM을 사용해 노이즈를 제거하고 원본 문장으로 복원하였다. 이를 통해 새로운 데이터셋 7_denoise를 생성하였고, 1_base 데이터셋과 비교하여 평가하였다.
| dataset | public f1 / accuracy |
| 1_base | 0.6599 / 0.6703 |
| 7_denoise | 0.7230 / 0.7329 |
LLM을 통한 노이즈 제거는 단순한 텍스트 수정이 아닌, 문맥과 의미를 고려하여 원본 문장을 추론한 결과이다.
이로 인해 텍스트의 품질이 향상되었고, 모델이 더 정확한 정보를 바탕으로 학습할 수 있게 되었다. 특히, 특수문자나 불필요한 잡음 요소가 제거되면서, 모델의 토크나이징 결과가 개선되고, 예측 성능이 향상되었다. 이는 Data-Centric 접근 방식에서, 텍스트의 품질이 모델 성능에 중요한 영향을 미친다는 것을 알게 되었다.
2-2. cleanlab을 활용한 relabel
이번 실험에서는, 노이즈 제거와 원본 문장 복원을 통해, 잘못된 타겟 값이 수정될 때 더 정확한 정보가 제공될 것이라 생각하여 7_denoise 데이터셋에 대해 Cleanlab을 적용하여 relabeling을 진행했다. 이 과정은 Cleanlab 실험 2의 규칙과 동일하게 수행되었으며, 노이즈가 포함된 데이터 (is_noise == 1)는 잘못된 타겟 값을 가지는 것이 아니기 때문에, relabelling 후 is_noise == 1인 데이터에서 변경된 타겟 값이 있을 경우에는 변경 전 타겟 값을 유지했다.
| 사용한 데이터셋 | number of label issues found |
number of label issues found(noise) |
base target ≠ changed target | public f1 / accuracy | |
| 7_denoise | 0.7230 / 0.7329 | ||||
| clean1 | 7_denoise | 1069 | 328 | 741 | |
| clean2 | clean1 | 412 | 220 | 908 | |
| clean3 | clean2 | 234 | 196 | 937 | |
| 25_relabel | clean3 | 222 | 192 | 958 | 0.8212 / 0.8259 |
7_denoise 데이터셋에 cleanlab을 적용했을 때 0.1이라는 큰 성능 향상이있었고 이는 Cleanlab을 통한 타겟 수정이 효과적이었음을 보여준다.
| dataset | base target ≠ changed target | public f1 / accuracy |
| 20_relabel | 948 | 0.8165 / 0.8138 |
| 25_relabel | 958 | 0.8212 / 0.8259 |
또한 relabelling만 적용한 20_relabel보다 relaeblling과 denoising을 통한 노이즈제거 및 원본 복원을 한 25_relabel의 성능이 좋은 것을 알 수 있었다. LLM을 통한 노이즈 제거 및 원본 문장 복원은 데이터의 품질을 크게 개선하였으며, Cleanlab의 relabeling 과정에서 더 정확한 타겟 수정이 가능하게 했다. 단순한 relabeling만으로는 한계가 있을 수 있지만, 노이즈 제거와 원본 문장 복원을 병행하면 성능 개선에 더 큰 기여를 할 수 있다.
2-3. 모델 기반 relabeling 데이터와 디노이즈된 데이터의 결합과 cleanlab
위의 2-2에서는 cleanlab을 활용하여 relabeling을 진행하였다면 이번 실험에서는 모델 기반으로 relabeling된 데이터를 사용하였다. 노이즈가 포함된 데이터는 7_denoise 데이터셋을, 노이즈가 포함되지 않은 데이터는 5_noise_detect를 기반으로 모델 학습을 통해 relabelling한 cleanlab_detect-bert_relabel 데이터셋을 사용한다. 합쳐진 이 데이터를 8_denoise_relabeling이라고 명명한다.
8_denoise_relabeling 데이터셋에 대해서 cleanlab을 진행하였다. 그 이유는 cleanlab_detect-bert_relabel가 학습될 때는 디노이즈된 데이터를 사용하지 않았기 때문에 디노이즈된 데이터를 기반으로 cleanlab을 적용한다면 추가적인 성능향상이 있을 것으로 예상하였다. cleanlab을 통해 생성된 데이터셋을 28_relabel로 명명한다.
| number of label issues found |
number of label issues found(noise) |
base target ≠ changed target | public f1 / accuracy | |
| 28_relabel | 252 | 219 | 998 | 0.8442 / 0.8404 |
| dataset | public f1 / accuracy |
| 28_relabel | 0.8442 / 0.8404 |
| 25_relabel | 0.8212 / 0.8259 |
| cleanlab_detect-bert_relabel | 0.8345 / 0.8372 |
cleanlab_detect-bert_relabel는 디노이즈되지 않은 데이터를 기반으로 학습되었기 때문에, 일부 타겟 값이 여전히 잘못될 가능성이 있다고 생각한다. 이를 보완하기 위해 Cleanlab을 통해 추가적인 Label Issue를 탐지하고 수정하였고, 그 결과 28_relabel을 통해 데이터셋의 품질이 더욱 향상된 것을 확인할 수 있었다.
실험3.
위와 동일한 5_noise_detect 데이터셋에서 is_noise==1인 데이터를 대상으로 LLM 프롬프팅을 진행하였다. denoise한 데이터셋을 확인하였을 때, 그럴듯한 제목으로 복원은 해주었으나 topic이 바뀐듯한 문장들이 몇몇 보였다. 그 예시는 다음과 같다.
| 이전 문장 | i\트햄과 z돌 토=!D06만{ 벌금 U계 |
| denoise 한 문장 | 트럼프와 돌 토우 0.6만에 벌금 부과 |
트햄을 보았을 때, 이전 문장은 아마 웨스트햄이 관련된 스포츠 기사로 추측된다. 하지만 denoise된 결과의 문장은 트럼프와 벌금이 나오며 정치, 경제 관련 기사로 변형되었다. 제대로 denoise되었다고 보기는 어려우나, 그럴듯한 기사 제목으로만 복원한다면 리라벨링 후 다시 데이터로 쓸 수 있을 것이라 판단하였다.
그래서 cleanlab을 이용하여 relabeling 후 제출을 하였으나, 결과는 처참했다.
| dataset | public f1 / accuracy |
| 1_denoise_llm | 0.3136 / 0.3105 |
먼저 eval 점수를 확인했을 때 이미 낮게 나왔기에 다시 한 번 확인차 제출하니 위의 결과가 나왔다. 데이터를 다시 한 번 확인해보니, cleanlab을 돌리면서 애매하게 denoise된 문장들도 모두 relabeling이 되면서 데이터의 질이 상당히 떨어졌다는 것을 알 수 있었다.
실험4.
LLM을 이용한 디노이징 과정에서 의미가 명확한 토큰 하나만이라도 온전히 얻어낸다면, 전체 문장을 복구하기 훨씬 용이해질것이라고 생각해봤고, 이를 기준으로 데이터를 디노이징하는 프롬프트를 작성해보았으나, 적절한 답변을 얻어내지 못해서 결과에 반영하지 않았다.
퓨샷 프롬프팅에서 해당 기준(토큰 기준 프롬프팅)에 알맞은 예시를 잘 찾아서 제공하고, 프롬프트 또한 개선한다면 더 좋은 성능을 얻을 수 있을 것이라고 생각한다.
실험5.
5_noise_detect 데이터셋에서 노이즈가 있다고 판단된 1602개의 문장에 대한 디노이즈를 시도하였다.
우선 prompting과정에서 few-shot으로 아래와 같은 디노이징 예시를 입력하였다.
입력된 제목: UrE }텔 垎4f학/술f진I회 대Li6沍j2
복원된 제목: 게시판 인텔 국제과학기술경진대회 대표단 발대식
입력된 제목: &아F 드]"빙 시뮬레V6
복원된 제목: 세아트 드라이빙 시뮬레이터
입력된 제목: 1r∼(u대는1유aX F대…하FF4p4n 9E< 본吔
복원된 제목: 10∼20대는 유튜브 세대…하루 4.4회 52분 본다
입력된 제목: -K. 미7d,객 잡5다
복원된 제목: SKT 미래 고객 잡는다
여기서 입력된 제목은 임의로 노이즈가 없는 데이터(복원된 제목의 데이터)에 노이즈를 입력한 제목이다. 전체 글자 중 50%의 글자에 임의로 노이즈를 입력하였으며, 노이즈가 입력될때 93%의 확률로 영어 및 숫자범위의 아스키코드로 교체하였고 7%의 확률로 한자 범위의 아스키코드 교체가 진행되었다.
이때 복원된 제목으로 적혀있는 원래 노이즈가 없는 제목은 디노이즈를 요구하는 문장과 같은 라벨의 데이터로만 입력하여 LLM이 denoise보다 generate를 시도하더라도 같은 주제의 text를 generate할 수 있도록 하였다.
같은 라벨의 few-shot 예시 데이터는 앞서 진행한 relabel실험을 통해 라벨오류를 수정한 cleanlab_detect-bert_relabel데이터셋에서 노이즈가 없는 1198개의 문장을 사용하였다. 그 결과 아래와 같이 LLM기반 디노이즈 결과물을 얻을 수 있었다.

위 사진과 같은 LLM기반 1602개의 디노이즈 결과를 아래 3가지 방법을 통해 baseline코드의 train데이터에 적용했다.
1. 노이즈데이터를 디노이즈 데이터로 교체(replace)
단순히 노이즈를 디노이즈 했으니, train데이터셋의 노이즈를 디노이즈 text로 바꾼의 결과물이다.
2. 노이즈데이터 유지하며 디노이즈 데이터 추가(add)
노이즈 데이터를 유지하면서, 디노이즈 데이터를 기존의 train set에 추가하였다. 이는 모델이 노이즈데이터와 디노이즈 데이터를 모두 학습하게 하여 다양한 상황에 더 잘 대응하도록 하여 모델의 일반화 성능을 높이기 위함이다.
3. 노이즈데이터 유지하며 디노이즈 데이터 추가 후 리라벨(add N relabel)
노이즈가 많은 경우 모델이 출력한 문장이 denoise보다 generate에 가까워질 수도 있다고 판단하였다. 같은 라벨 데이터를 예시로 few-shot prompting을 하더라도 생성된 text의 주제가 달라질 수 있다고 생각했다. 따라서 앞서 2.3.2 Encoder 모델 기반 relabeling에서 1002개의 라벨을 변화시킨 kakaobank/kf-deberta-base모델의 checkpoint를 활용하여 LLM이 생성한 데이터를 ralabeling 시도하였다.
위 3가지 방법을 이용하여 baseline의 trainset을 변경시켰으며, 제출한 결과는 아래와 같다.
| dataset | public f1 / accuracy(leaderboard) |
| clenlab_detect-bert_relabel-denoise_replace_LLM | 0.8319 / 0.8355 |
| clenlab_detect-bert_relabel-denoise_add_LLM | 0.8419 / 0.8466 |
| clenlab_detect-bert_relabel-denoise_add_LLM_relabel | 0.8042 / 0.8093 |
결과적으로 디노이즈 데이터를 단순히 추가하여 모델의 일반화 성능을 높인 데이터셋이 제일 높은 성능을 보였다.하지만 예상과 다르게 생성한 데이터에 추가적으로 relabeling을 진행한 후 제출한 결과의 점수는 낮은 점을 확인하였다. 이에 대한 이유를 아래와 같이 분석했다.
1. denoise text relabeling에 사용된 인코더모델의 학습오류
인코더 모델의 학습이 잘못되거나 부족하여 디노이즈되어 새롭게 생성된 text에 대해 잘못된 relabel을 했다. 따라서 text-label간 mismatch가 발생하여 baseline이 잘못된 방향으로 학습되었다.
2. denoise text relabeling 과정에서 데이터의 일관성 상실
Relabeling을 통해 라벨과 텍스트 간 주제는 명확히 매칭되었다. 하지만 baseline 모델이 뉴스 제목을 기반으로 라벨을 추론할 때, 단순히 핵심 키워드만을 사용하는 것이 아니라 문맥, 어조, 감정, 형식, 구조, 어휘 등의 다양한 측면을 고려한다고 가정할 수 있다. 라벨을 변경하면서 이러한 라벨 간의 인간이 파악하기 힘든 통일성이 깨졌기 때문에, 모델이 올바른 방향으로 학습하지 못하게 되었을 가능성이 있다.
2.5. augmentation
2.5.1. BackTranslation
역번역을 통한 증강의 장점은 라벨값이 달라지지 않고 데이터를 증강할 수 있다고 생각하여 이번 실험을 진행하게 되었다.
실험1. MTM을 활용한 BT
가장 먼저 모델의 성능을 확인해보았다. 노이즈가 심한 데이터는 BT의 효과가 없을 것이라 판단하여, 5_noise_detect 데이터셋 중 노이즈가 포함되지 않은 데이터에 대해서만 실험을 진행하였다.
모델 facebook/m2m100_418M을 사용하여 한국어를 영어로, 다시 영어를 한국어로 역번역을 진행하였다.
| 원본 text | BT text |
| 닷새째 경찰에 포위된 홍콩 이공대 | 홍콩 경찰 5명 체포 |
| 빈자리 드문 세종 국무회의장 | 희귀한 국무장관 |
BT의 품질은 좋지 않았으며. 특히 영어를 한국어로 번역하는 품질이 좋지 않았다. 이외에도 MTM 모델에 대해 성능을 확인해보았는데 마찬가지로 BT의 품질이 좋지 않았으며 특히 영어를 한국어로 번역하는 품질이 좋지 않았다. 따라서 MTM 모델을 사용하여 실험을 진행하지 않았다.
실험2. pororo를 활용한 BT
pororo 라이브러리를 사용해서 9_relabel 데이터셋 중 is_noise==0(노이즈를 포함하지 않는) 데이터를 역번역하였다.
| dataset | public f1 / accuracy |
| 9_relabel | 0.8083 / 0.8116 |
| 3_augmentation_3989 | 0.8144 / 0.8175 |
Pororo를 활용해 Back Translation을 수행하고, KR-SERT 모델을 사용하여 역번역 전 문장과 역번역 후 문장 간의 Cosine Similarity를 계산하였다. 이를 통해 역번역된 문장이 원본 문장과 얼마나 유사한지를 분석하고, 데이터 증강에서 BT의 효과를 평가하고자 했다.
| 원본 text | BT text | cosine similarity | 결과 분석 |
| 백두대간의 가을 하늘 | 백두대간의 가을 하늘 | tensor(1.0000) | 완전 일치 |
| 힐러리 대선보도에 불만…278일만에 첫 기자회견 | 힐러리의 278일 만의 첫 기자회견 | tensor(0.7323) | 부분적인 의미변경 |
| 北 36년만의 당대회 맞아 김정은 우상화…주민불만 커져 | 북한에서 36년 만에 김정은의 아이돌화가 커지고 있다. | tensor(0.4739) | 의미 변화 또는 정보 손실 |
결과분석을 3가지로 분류하였다. 완전일치는 원본과 완전히 동일하게 역번역된 경우로 이는 BT 효과가 사실상 없고 데이터 증강의 이점을 기대할 수 없다. 부분적인 의미변경은 문장의 일부 정보가 축약되었지만 주요 의미는 유지되었다. 이러한 경우는 데이터 증강에 긍정적인 영향을 줄 수 있으며, 적절한 변형으로 간주할 수 있다. 의미변화 또는 정보손실은 원본과의 유사성이 줄어들어 새로운 정보로 간주될 수 있지만, 의미 왜곡이 심한 경우 모델 학습에 혼란을 줄 수 있다.
증강 전 데이터 9_relabel보다 증강 후 데이터 3_augmentation_3989 성능이 향상된 것을 확인하였지만, 3가지 분류에 따른 cosine similarity의 범위를 정확하게 설정하지 못해 BT 실험을 종료하였다.
2.5.2. LLM
EXAONE-3.0-7.8B-Instruct 모델을 사용하여 데이터 증강을 하였다.
실험1. 기존 뉴스 기사 제목을 활용한 기사 생성 및 새로운 제목 생성
이번 실험은 노이즈가 있는 데이터에서 LLM을 활용하여 디노이징을 수행하고, 이를 통해 데이터의 품질을 향상시키고자 하였다. 노이즈가 있는 데이터는 라벨이 정확하다는 가정 하에, 디노이징된 데이터를 기반으로 기사를 생성하고 해당 기사에 대한 제목을 생성하여 데이터 증강을 시도하였다.
1-1. 기사 및 제목 생성
27_relabel 데이터셋의 디노이징된 텍스트를 기반으로 기사를 생성하고, 해당 기사에 대한 제목을 생성하였다. 생성된 제목의 수는 원본 기사와 동일하게 유지하였다. 각 라벨 별로 약 66개 씩 450개 가량을 증강하였다.
생성된 기사와 제목의 예시는 아래와 같다.
| 원래 제목 | 삼성전자, 500억 원 규모 OLED 생산 라인 구축 |
| 생성된 기사 내용 | 삼성전자가 차세대 디스플레이 기술인 OLED(유기발광다이오드) 시장에서의 경쟁력을 강화하기 위해 5억 달러(약 6,060만 원) 규모의 OLED 패널 생산라인을 새롭게 구축한다고 발표했다. 이번 투자는 2023년 상반기에 착공하여 3년간의 공사 기간을 거쳐 4년 후인 8월에 완공될 예정이다. 1조 원 이상의 시장 규모로 성장이 예상되는 OLED 시장을 선점하기 위한 전략적 결정으로 보인다. |
| 새로운 제목 | "삼성전자, 차세대 OLED 기술 강화 위해 대규모 생산 라인 구축" |
1-2. 특수문자 처리
생성된 제목에서 자주 등장하지만 테스트 데이터에는 포함되지 않은 특수문자를 제거하거나 다른 특수문자로 대체하였다.
1-3. 리라벨링
CleanLab을 통해 라벨 수가 적어질 때까지 반복적으로 리라벨링을 수행하였다. 이 과정은 데이터 품질을 지속적으로 개선하는 데 중점을 두었다. 이는 새롭게 증강된 데이터가 다른 라벨로 분류될 수도 있다고 생각하였기 때문이다.
| 사용한 데이터셋 | accuracy/f1 | |
| 27_relabeling | 0.8217 / 0.8177 | |
| 6_augmentation_3240 | 27_relabeling | 0.8206 / 0.8173 |
증강 결과, accuracy와 f1 모두 소폭 감소하였다.
실험2
28_relabel의 노이즈를 포함하지 않는 데이터만을 활용하여 4710개의 데이터를 증강을 하였다. 증강 시, 각 target의 비율이 일정하게 유지되도록 target별 증강된 데이터의 수를 다르게 설정하여, 원본 데이터셋의 타켓 분포가 왜곡되지 않도록 하였다.
| dataset | public accuracy / f1 |
| 28_relabel | 0.8442 / 0.8404 |
| 5_augmentation_7510 | 0.8432 / 0.8394 |
증강 전 데이터셋인 28_relabel의 성능이 증강된 데이터셋 5_augmentation_7510보다 더 우수한 결과를 보인다. 28_relabel 데이터셋은 Cleanlab 또는 모델 기반으로 relabeling이 적용되었지만, relabeling된 타겟 값이 완벽하게 정확하지는 않는다. 증강 시, 잘못된 타겟 값을 가진 데이터도 증강에 포함되었다. 이로 인해 잘못된 타겟 값을 가진 샘플이 더욱 많아지게 되어, 증강된 데이터셋에서 오히려 노이즈가 증가하는 결과를 초래했다.
실험3
앞선 LLM 증강 실험에서 사용한 프롬프트와 증강된 데이터를 살펴보았을 때, few-shot 없이 프롬프트를 사용한 점, 시스템 메시지를 사용하지 않은 점, 증강된 데이터가 원본 데이터와 많은 차이를 보이는 점 등이 눈에 띄었다. 그래서 few-shot을 총 7개를 주어 모든 클래스에 대한 출력 예시를 제공했다. 시스템 메시지를 통해 엄격한 조건을 추가하였다. 고유명사를 탐지하면 치환할 것, 입력에서 사용한 단어와 최대한 겹치지 말 것, 등의 조건을 이용하여 생성했다. 각 문장에 대해 5배씩 증강을 했다. 제출 후 결과적으로 성능이 올랐으나 대회 마감 전날이였기 때문에 제출 횟수와 실험 시간 등이 부족하여 2배수부터 하나씩 추가하면서 비교하는 과정을 실험에서 담아내지 못한 점이 가장 아쉽다. 그리고 문장 유사도 검사 등을 활용하여 정량적으로 문장의 다양성을 평가하지 않았던 점도 아쉽다. 이런 방식을 사용하여 중복 문장을 제거하는 과정을 거쳤다면 더 큰 성능 상승폭을 기대할 수 있었을 것이다.
| dataset | public accuracy / f1 |
| 28_relabel | 0.8442 / 0.8404 |
| 10_rda_16494_exaone_agument_x5 | 0.8477 / 0.8433 |
2.5.3. sentence mix
이는 단순히 같은 라벨의 제목을 2개 샘플링하고, 제목의 절반씩 mix를 하는 실험적 방법론이다. 예시는 아래와 같다.
예시 1번.
게임 관련 뉴스제목 A. SKT T1 페이커 선수, 롤챔스 우승!
게임 관련 뉴스제목 B. 크래프톤, 배틀그라운드 국제 대회 개막
생성된 새로운 게임관련 뉴스제목 C-1(정방향). 크래프톤, 배틀그라운드 롤챔스 우승!
생성된 새로운 게임관련 뉴스제목 C-2(역방향). 국제 대회 개막 SKT T1 페이커 선수
예시 2번.
연예 관련 뉴스제목 A. 이효리, 서울에 스타벅스 건물 지어
연예 관련 뉴스제목 B. [종합] 서울 인사동에서 엔믹스 귀여워…
생성된 새로운 연예관련 뉴스제목 C. [종합] 서울 인사동에서 스타벅스 건물 지어
이러한 방식으로 증강을 진행할 경우 예시1번과 같이 문맥적으로 말이 되지않는다고 생각하였다. 특히 예시 2번과 같이 핵심 키워드를 포함하지 않는 문장도 생성될 것이라 생각하였다.
하지만 2.4.5.LLM 파트의 LLM이후 relabel이 실패한 2번 이유(데이터의 일관성 상실)를 연장해서 생각해본다면, sentence mix 이후 문장에 핵심 키워드가 없더라도 label별 문맥, 어조, 감정, 형식, 구조의 일관성을 통해 모델이 충분히 분류할 수도 있을 것이라고 판단했다.
또한 LLM을 활용한 증강은 훨씬 문맥적으로 부드럽게 생성해주지만 문장의 어조와 감정, 형식이 label별로 편향되는 것이 아닌 LLM 모델별로 편향되기 때문에 오히려 작은 파라미터의 모델에서 성능이 떨어질 수도 있다고 생각하여 LLM 증강이 아닌 sentence mix와 같은 형식의 증강을 시도해보았다.
베이스가 되는 데이터셋은 relabel만 완료한 5_noise_detectclenlab_detect-bert_relabel 데이터셋(이하 only_relabel)과 text denoise, label denoise가 전부 완료된 5_noise_detectclenlab_detect-bert_relabel-denoise_add_LLM(이하 all_denoise)을 활용하였다.
라벨별로 text 두개씩 랜덤 샘플링하여 절반씩 잘라 하나의 문장을 하나 만들경우 이를 1회로 설정하고, 해당경우를 라벨별로 200번에서 1000번까지 반복하면서 데이터를 증강하였다. 또한 예시 1번 C-1과 같이 정방향으로 mix할경우 forward(fwd)로 데이터셋에 기록하였고, C-2예시와 같이 역방향으로 mix할 경우 backward(bwd)로 기록하였다.
| dataset | public f1 / accuracy(leaderboard) |
| only_relabel_fwd300 | 0.8436 / 0.8461 |
| all_denoise_fwd800_bwd200 | 0.8435 / 0.8476 |
| all_denoise_fwd800_bwd200(stratified shuffle) | 0.8471 / 0.8506 |
| all_denoise_fwd1000_bwd200 | 0.8387 / 0.8429 |
해당 실험은 relabel만 했을경우와 denoise까지 진행했을 경우 두 경우 모두에서 리더보드 SOTA를 달성하였다.
반복횟수를 늘릴 경우 로컬 validation dataset에서 성능이 90%이상으로 지속적으로 오르는 모습을 보였지만, 오히려 특정 한계에 도달하는 것이 아닌 꾸준히 오르는 모습을 보여 overfitting이라 판단하였다. 따라서 적절한 횟수로 증강한 데이터셋을 제출하여 위와 같은 결과를 얻을 수 있었다.
라벨별로 정방향으로 800번, 역방향으로 200번 증강하여 총 7천개의 추가 데이터를 만들었을 경우 제일 높은 성능을 얻었으며, 이를 추가 개발된 stratified shuffle 방식으로 모델에 학습했을 경우 성능이 높아짐을 확인했다.
2.6. preprocessing
2.6.1. 한자 사전
뉴스 기사 제목은 짧은 문장에 기사 내용을 나타내야하기 때문에 함축적인 표현을 적극적으로 사용한다. 그렇기 때문에 일반 문장에 비해 한자 사용 빈도가 높은 편인데, 이때 사용하는 한자 단어들은 주제를 담고 있는 핵심적인 단어들이다. 따라서 문장에서 한자 단어의 뜻을 모델에 잘 학습시키고자 하는 목적을 가지고 뉴스 기사에 사용된 모든 한자의 뜻을 찾아 한자 사전을 만들어 전처리에 사용했다.
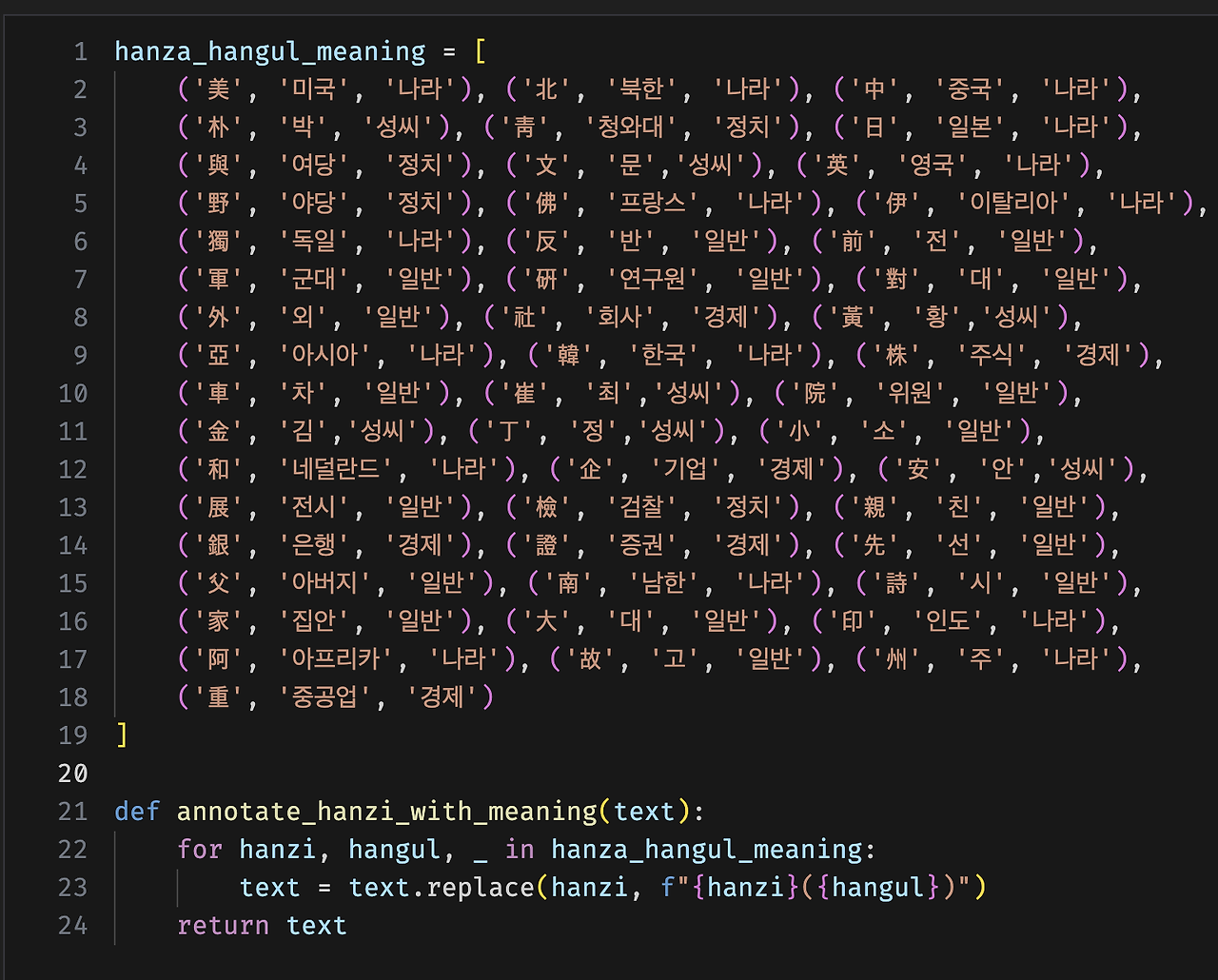
예를 들어 靑은 靑(청와대)로 교체하였고 重은 重(중공업)으로 교체하였다. 한자에는 여러가지 뜻이 있으나 뉴스 기사에서 무겁다는 표현을 위해 重자를 사용하는 경우는 거의 없었다. 최대한 뉴스 기사 데이터의 특성을 활용하여 가장 적합한 단어 뜻을 추가해주었다. 이렇게 한자 사전을 추가한 데이터셋과 대회 제공 원본 데이터셋을 비교했을 때 성능이 큰 폭으로 향상되었으나, 데이터셋이 노이즈 복구, 리라벨링, 증강 등이 충분히 이루어진 데이터셋에 적용했을 때는 성능에 큰 차이가 없거나 오히려 소폭 감소했다. 이는 해당 전처리 자체가 유의미한 성능 향상을 이뤄낸 것이 아닌 노이즈 데이터에 약간의 노이즈 개선 효과를 주었던 것이라고 판단하였고, 데이터셋이 커짐에 따라 자연스럽게 문맥에서 한자 단어를 이해하는 것이라고 생각했다. 그리고 전처리하지 않았을 때가 실제 테스트 데이터셋과 유사한 형태를 띄기 때문이라고 생각했다. 따라서 이후 한자 사전을 이용한 전처리는 사용하지 않았으며, 전처리 방법에 대한 실험보다는 최대한 테스트 데이터셋과 유사한 형태의 훈련 데이터셋을 만들고자 집중했다.
2.7. 최종 제출한 결과에 대한 설명
2.7.1. 제출 1
1. 노이즈 유무 판별
clean-lab 기반으로 1600개에 제일 가까운 noise를 detect한 5_noise_detect 결과 데이터를 이용하였다.
2. 모델 기반 relabeling
해당 데이터 중 라벨이 맞는 데이터(노이즈가 있는 데이터)를 train데이터로 학습시키고, 라벨이 틀린 데이터(노이즈가 없는 데이터)를 test데이터로 추론시킨 kakaobank/kf-deberta-base모델을 활용하였다. 결과적으로 1002개의 라벨을 수정하였다.
3. LLM 기반 디노이즈 데이터 추가
1번에서 노이즈가 있다고 판단된 데이터를 디노이징하기 위해 2번에서 라벨이 수정된 데이터를 활용하여 같은 라벨의 데이터를 few-shot으로 넣었다. 해당 결과를 5_noise_detectclenlab_detect-bert_relabel-denoise_add_LLM로 저장하여 4번 작업에 활용하였다.
4. sentence-mix
3번에서 얻은 데이터를 정방향으로 800번, 역방향으로 200번 증강 하여 가장 높은 성능을 얻은 all_denoise_fwd800_bwd200 데이터를 저장하였다.
5. stratified shuffled split
4번의 데이터를 stratified shffle하여 모델에 입력한 결과를 제출하였고, 최종적으로 public leaderboard score f1 0.8471, accuracy 0.8506로 팀 SOTA를 기록하여 최종 제출에 포함하였다.
2.7.2. 제출 2
2.5.3의 sentence-mix 방식으로 증강한 sentence-mix2 데이터와 2.5.2의 LLM 프롬프트 방식으로 증강한 데이터를 병합하여 제출하였다. 병합하는 과정에서 겹치는 데이터는 sentence-mix2 데이터의 데이터를 유지하는 방식으로 진행했다. sentence-mix 데이터는 클래스별 불균형이 있어서 해당 실험 결과를 참고하여 클래스 별 분포를 맞춰주었다. 가장 데이터 수가 적었던 4번과 5번 레이블(각 6189, 6065개)을 제외하고 나머지 레이블은 약 6500개 내외로 맞춰주었으며, evaluation에서 가장 잘 못맞췄던 2번 레이블은 6728개에서 따로 제거하지 않고 그대로 유지하였다. 그렇게 46494개인 데이터셋을 만들어 제출하였고, public 기준 f1-score가 sentence-mix2에 비해 0.0014 올랐다. 그러나 대회 끝날 무렵 팀원이 sentence_mix3을 제출하여 팀 내 제출 기록을 갱신하였다. 대회 막바지에 진행되어 제출 횟수와 시간이 충분하지 못해 sentence_mix3와 병합한 데이터셋을 만들지는 못한 점이 아쉬웠다. 2.7.2는 f1-score 기준 팀 내 제출 기록 중 2등이며 균형을 맞춘 데이터셋이라는 점을 들어 최종 제출 2건에 포함시켰다.
| dataset | public accuracy / f1 |
| sentence_mix1 | 0.8461 / 0.8436 |
| sentence_mix2 | 0.8476 / 0.8435 |
| 10_rda_16494_exaone_agument_x5 | 0.8477 / 0.8433 |
| 12_rda_46494_exaone_agument_x5_sent_mix2_balance | 0.8490 / 0.8449 |
| sentence_mix3 (Team SOTA) | 0.8506 / 0.8471 |
3. 프로젝트를 위해 개발한 기능
3.1. streamlit 시각화
이번 프로젝트에서는 Streamlit을 통한 시각화를 시도하였다. 이번 프로젝트 주제가 Data Centric이였던 만큼 간편하고 통일된 데이터 시각화 방법이 필요할 것이라고 생각했다.
데이터에 대해 직접 관찰해보고싶은 사항들은 최대한 하나의 페이지 안에서 한번에 볼 수 있도록 구성하였다.
3.1.1. 단순 데이터 및 데이터 분포 시각화
우선 데이터를 깔끔하게 확인할 수 있도록 단순 데이터 출력 및 라벨값에 따른 데이터 분포를 시각화하였다.
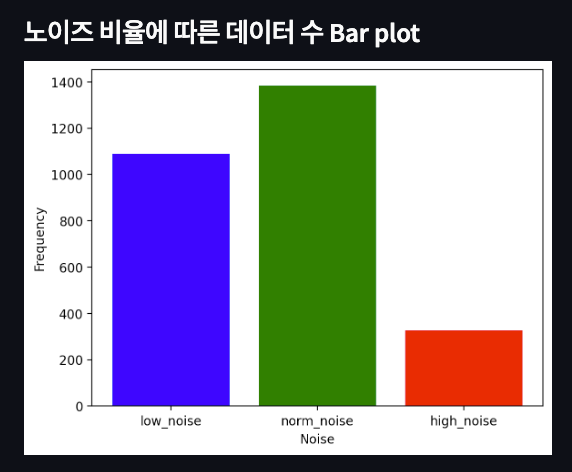
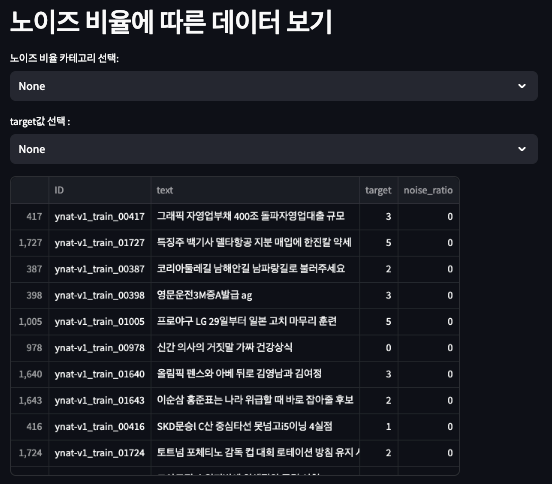
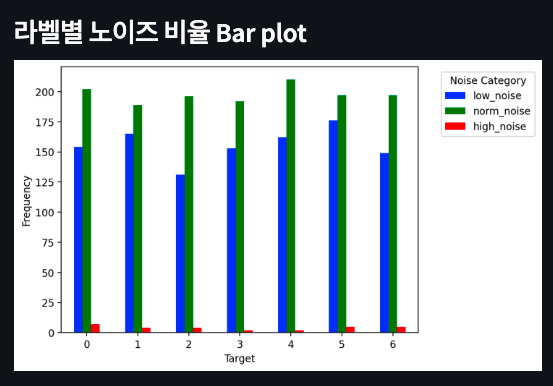
3.1.2. 노이즈 비율 및 분포 시각화
또한, text의 노이즈 정도를 특수문자 비율에 따라 시각화할 수 있도록 아래와 같이 페이지를 구현하였다.
3.1.3. 토큰화 시각화
아래와 같이 토큰화 결과도 볼 수 있는 페이지를 구현하였다.

3.1.4. CleanLab 리라벨링 결과 시각화
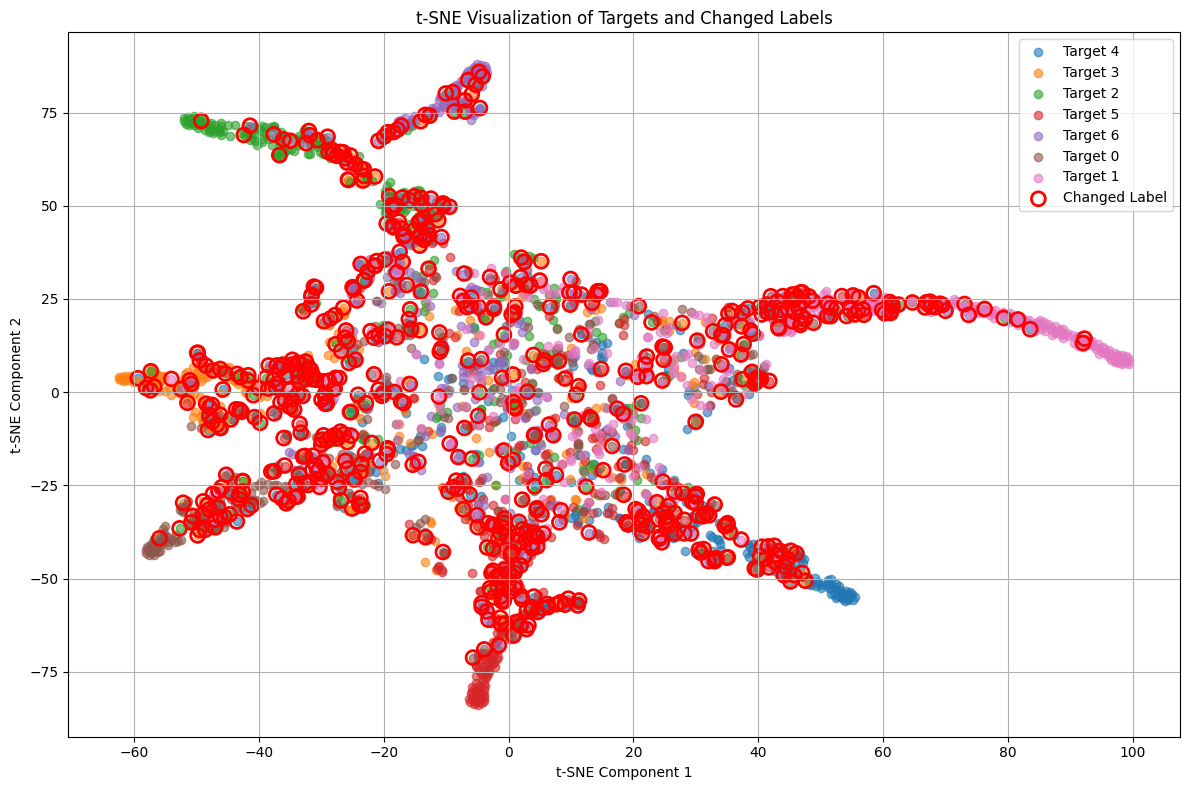
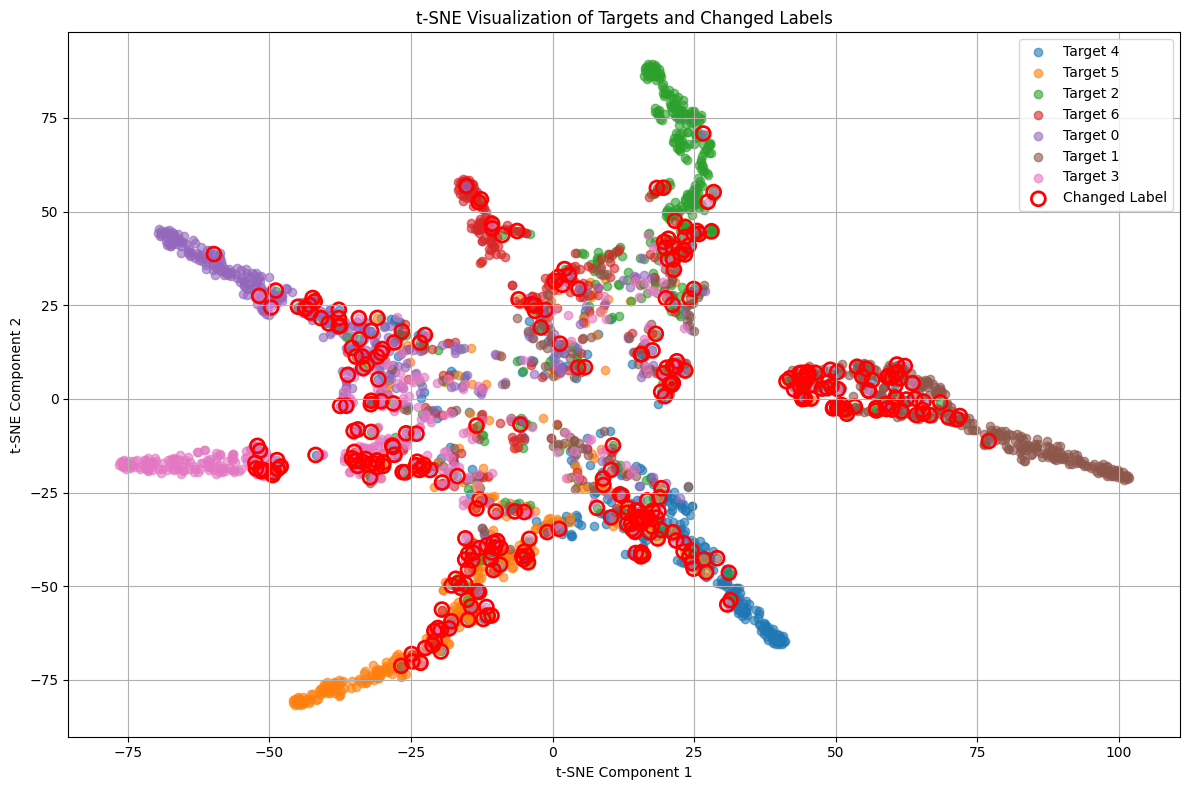
CleanLab을 통해 리라벨링된 데이터를 활용하여, 새롭게 변경된 데이터의 노이즈 비율을 시각화하였다. 노이즈가 없는 데이터는 라벨이 부적절한 경우를 나타내고, 노이즈가 있는 데이터는 라벨이 적절한 경우를 나타내기 때문에, CleanLab의 성능을 평가하기 위한 중요한 지표로 사용될 수 있었기 때문이다.
이 그림은 t-SNE 기법을 사용하여 데이터의 예측 레이블과 변경된 레이블을 시각화한 것이다. 각 색상은 서로 다른 타겟을 나타내며, 빨간 원으로 표시된 점들은 레이블이 변경된 데이터를 나타낸다. 변경된 레이블이 기존 클래스와 어떻게 구분되는지를 살펴보면, 모델의 성능 향상에 기여한 레이블 수정의 효과를 이해하는 데 도움이 되었다.
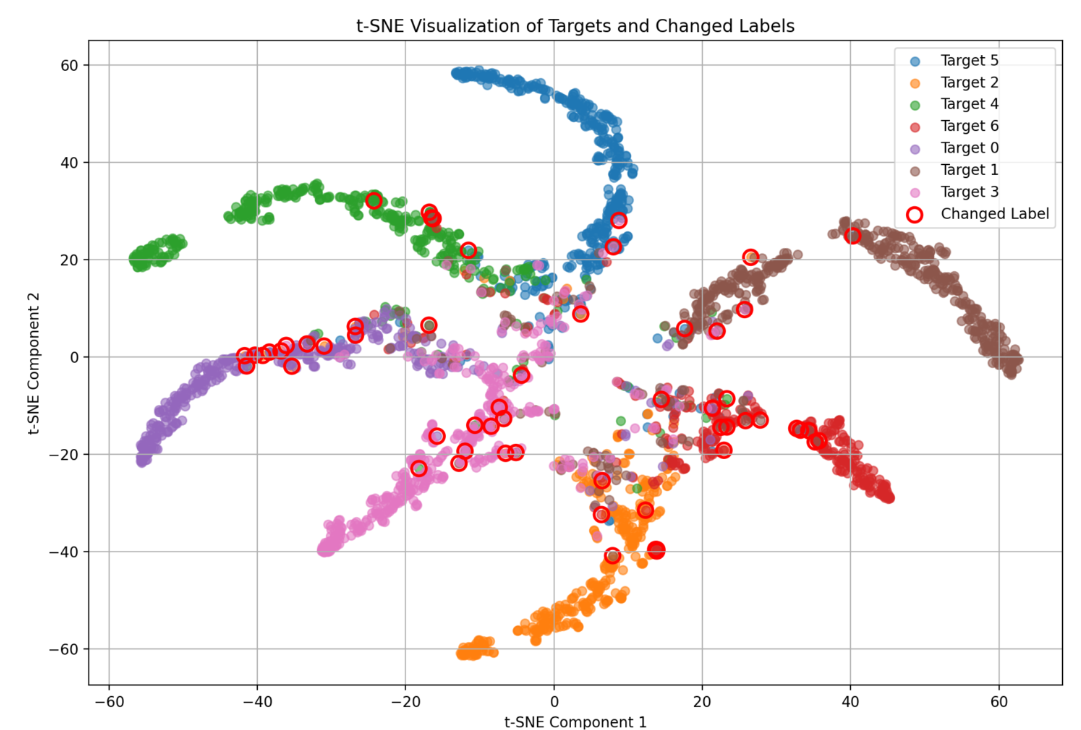
이와 같은 데이터 시각화의 목적은 직접 확인해보면서 더 나은 인사이트를 얻어내기 위함이었고, 다양한 관점에서 볼 수 있도록 더 많은 페이지를 구현해보고싶었으나, 시간 관계상 추가하지 못한 아쉬움이 있다.
3.2. 데이터셋 메타 데이터 생성 및 업로드 툴
Data-Centric 프로젝트에서 데이터셋을 잘 관리하는 것은 협업 효율을 극대화 시킬 수 있는 가장 중요한 포인트라고 생각했다. 그래서 어떻게 하면 각자 만든 데이터를 모두가 함께 공유하고 쉽게 확인할 수 있을까 생각해보았다. 우선 Hugging Face로 관리하는 방법을 생각했으나 데이터셋을 csv 형태로 올릴 수 없고 변환하여 올려야한다는 점과 private team에서 업로드한 데이터는 웹에서 직접 확인할 수 없다는 점이 불편했다. 그래서 구글 드라이브 공유 폴더로 공유하되 업로드할 때 자동으로 데이터셋의 데이터 수, 분포, 제작 방식 등의 메타데이터를 생성할 수 있으면 좋겠다고 생각하여 Streamlit과 FastAPI로 툴을 만들고 GCP에 머신을 생성하여 배포했다. duckdns와 letsencrypt로 https 인증서와 도메인을 연결하여 웹 서비스 형태로 팀원들에게 url을 공유했다. 나머지 팀원들이 프로젝트에 집중할 수 있도록 개인 저장소에서 따로 관리하였다. 코드와 동작 스크린샷은 깃허브 저장소에서 확인할 수 있다.
3.3. 구글 드라이브 실험 결과 파일 생성
데이터셋 업로드 툴을 통해 구글 드라이브에 데이터셋을 관리되기 때문에 해당 데이터셋을 사용하여 실험한 결과 파일들 또한 구글 드라이브를 통해 쉽게 관리할 수 있었다. 자동으로 추론 결과 csv 파일을 구글 드라이브에서 데이터셋 폴더를 탐색하고 해당 폴더에 업로드하는 코드에 기능을 추가했다. 또한 추론 결과에 대한 클래스 분포 json 파일을 생성하여 함께 업로드하도록 했다. wandb에서 기록하는 실험명과 동일한 이름으로 업로드하였기 때문에 대회 제출 시 해당하는 실험명을 기입하여 사용 데이터 - 실험 로그 - 추론 결과를 한번에 파악할 수 있었다. 이렇게 하여 협업 과정에서 소통 비용을 크게 절감할 수 있었다.
3.4. 허깅페이스 모델 및 데이터 업로드
모델과 데이터를 효율적으로 관리하기 위해 Hugging Face를 통한 업로드 및 다운로드 방식을 도입하였다. 데이터 업로드는 별도의 파일로 진행할 수 있도록 구현하였고, 모델 업로드 및 다운로드, 데이터 다운로드는 baseline 코드에 통합하였다. baseline 설정 파일(config)에 지정된 모델과 데이터가 로컬 폴더에 존재하지 않을 경우, Hugging Face 팀스페이스에서 해당 모델과 데이터를 자동으로 다운로드하도록 하였다. 이와 함께 학습이 완료된 모델은 자동으로 Hugging Face에 업로드할 수 있도록 구현하였다.
이를 통해, 팀원들이 로컬 환경에 관계없이 동일한 버전의 모델과 데이터를 사용하여 실험을 재현할 수 있는 일관성을 높였고, config에 모델명과 데이터명을 작성하는 것 만으로 자동으로 데이터셋과 모델을 다운로드 할 수 있도록 하여 편의성과 협업 효율성을 높였다.
3.5. Github 세팅
지난 프로젝트에서 피드백 받았던 부분 중 하나는 Linter를 사용하지 않아 코드 컨벤션, 패키지 import 정렬, 포맷팅이 이루어지지 않았던 점이다. 그래서 Makefile과 pyproject.toml에 Ruff를 적용하여 pep8 코딩 컨벤션을 준수하고 포맷팅을 자동으로 수정하도록 세팅하였다. workflow와 pre-commit 또한 적용하여 커밋 단계에서 자동으로 검사를 진행하고, PR 단계에서도 검사를 통과하지 못하면 수정하여 다시 올릴 수 있도록 설정했다.
4. 개인 회고
이번 프로젝트에서 팀에 가장 많은 기여를 한 부분은 실험하기 좋은 환경을 구성하고자 한 부분이다. 깃허브 Linter 도입, 데이터 업로드 및 메타 데이터 생성 툴 구축, 실험 결과 자동 업로드 환경 구성, 실험 분석을 위한 클래스별 f1, accuracy score 로그 등을 통해 수 많은 데이터셋을 생성하는 Data-Centric 프로젝트에서 팀원들이 데이터 파일 관리에 대한 고민을 최대한 적게 할 수 있도록 노력했다. 여러 도구와 환경을 도입할 때 팀원들이 필요성에 공감하면서 쉽게 사용할 수 있도록 따로 적응이 필요하지 않은 내용 위주로 반영하여 빠르게 정착할 수 있었다. 그렇게 실험 결과와 데이터셋을 쉽게 공유할 수 있었던 점은 큰 장점이였으나 실험 과정을 자세하게 공유하지 못했다. 팀원의 실험보다는 자신의 실험, 실패한 실험보다 성공한 실험의 결과 위주로 더 눈길이 갔으며, 각자의 실험 과정을 문서로 작성하는 방법이 달랐던 점이 과정에 대한 공유를 어렵게 했던 것 같다. 또한 환경적인 부분에 시간을 쏟아 많은 실험을 진행하지는 못했다. 특히 데이터셋의 클래스 분포와 클래스별 evaluation 점수에 많은 고민을 했다. 전반적으로 ‘스포츠’ 주제는 특징적인 단어가 많고 비교적 좁은 분야이기 때문에 잘 맞추나 ‘사회’ 주제는 ‘경제’나 ‘정치’ 주제와 쉽게 혼동할 수 있으며 비교적 넓은 분야이기 때문에 모델이 잘 맞추기 못했을 뿐더러 ‘사회’ 클래스로 예측하는 빈도 자체가 낮았다. 이를 개선하고자 했으나 해당 고민이 많이 반영된 실험을 만들지 못해서 아쉽다. 해당 실험 전에 꼭 선행되어야 했던 노이즈 탐지 및 노이즈 복원에 시간을 많이 소모한 점 때문에 클래스별로 분리하여 이진 분류 실험이나 특정 클래스를 크게 증강한 데이터셋을 만드는 등의 실험을 만들지 못했다. 또한 각자의 아이디어로 실험 계획과 실험 결과를 공유하다보니 실험 아이디어가 고갈된 팀원들이 붕 뜨는 문제가 생겼다. 다음 프로젝트에서는 꼭 실험을 함께 설계하고 생성하여 실험 풀을 생성하고 실험 풀에서 본인을 할당하는 방식으로 진행하고 싶다. 또한 팀원이 진행하는 실험에 내가 참여하는 것이 마치 아이디어를 뺏거나 실험을 방해하는 것 같아 주저했는데, 다음 프로젝트에서는 적극적으로 팀원이 진행하던 실험에 참여하여 아이디어를 추가하고 살을 붙이고 싶다. 또한 원활한 실험 과정 공유를 위해 실험 보고서 포맷을 만들어 관리하는 규칙을 도입하고 싶다.
'네이버 부스트캠프 AI Tech 7기 > 후기 & 회고' 카테고리의 다른 글
| AI Research Engineer 모의 면접 후기 (5) | 2024.12.18 |
|---|---|
| [네이버 부스트캠프 AI Tech 7기] Level3 수능 문제 풀이 모델 생성 프로젝트 최종 리포트 (3) | 2024.12.03 |
| [네이버 부스트캠프 AI Tech 7기] Level2 MRC - ODQA 프로젝트 최종 리포트 (2) | 2024.10.26 |
| [네이버 부스트캠프 AI Tech 7기] Level2 MRC - ODQA 프로젝트 2주차 회고 (0) | 2024.10.18 |
| [네이버 부스트캠프 AI Tech 7기] Level2 MRC - ODQA 프로젝트 1주차 회고 (4) | 2024.10.12 |



댓글