반응형
위 강의노트는 고려대학교 산업경영공학부 대학원 강필성 교수님의
비정형데이터분석 (Text Analytics) 을 듣고 정리한 강의노트입니다.
Syntax Analysis (구문 분석)
Syntax Analysis
- 형식 문법의 규칙을 따르는 위계구조/형태/문장구조를 분석하는 과정
Parser
- 입력 문자열을 특정한 문법에 걸맞게 변환(파악)하는 알고리즘
- Directionality(방향성)
e.g.) top-down / bottom-up - Search strategy(탐색전략)
e.g.) depth-first, breadth-first
Parsing Representation
- Tree vs List
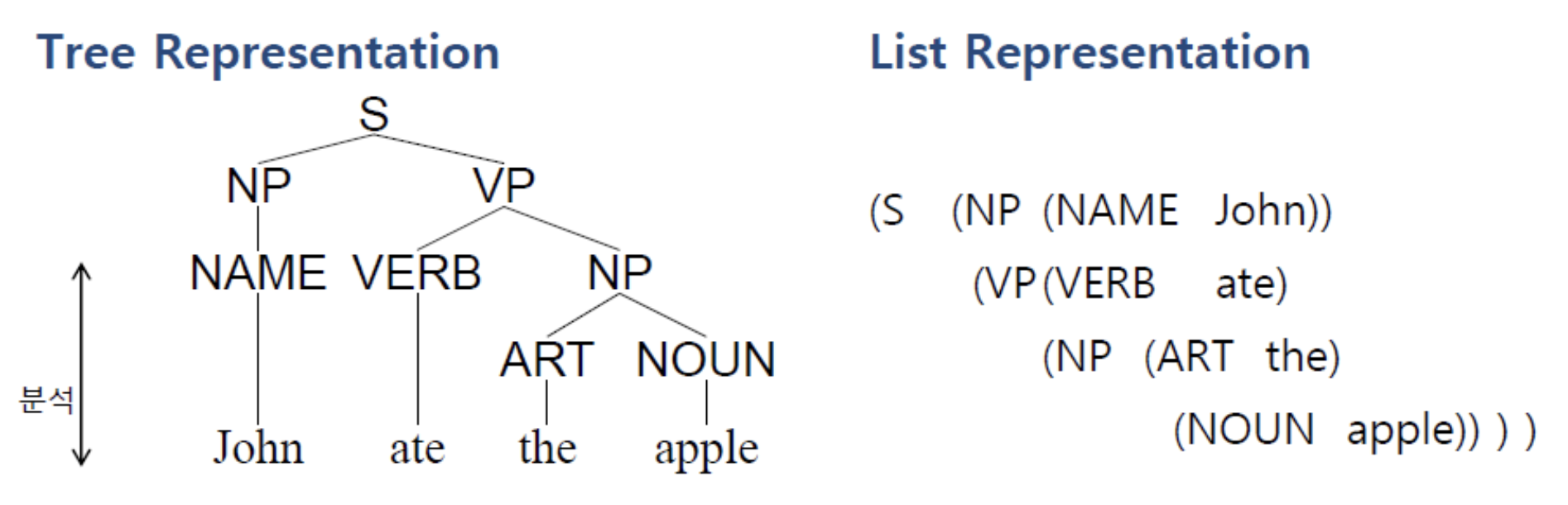
- Meaning
- 문장 S는 명사절 NP와 동사절 VP로 구성된다.
- 명사절은 이름(John)을 가진다.
- 동사절은 동사(ate) 과 다른 명사절을 가진다.
- 다른 명사절은 관사(the)와 명사(apple)을 가진다.
Ambiguity
- Lexical ambiguity (어휘적 모호성)
- 하나의 같은 단어가 서로 다른 형태소(품사)로 사용됨
- 어휘적 모호성이 구조적 모호성(structural ambiguity)을 야기함

- Structural ambiguity (구조적 모호성)
- 하나의 문장이 다른 방식으로 이해될 수 있음
- 품사를 전부 동일하게 태깅되지만 다른 의미로 해석됨

Other Topics in NLP
Language Modeling (언어 모델링)
Probabilistic Language Model
- 문장에 확률을 부여 (확률이 POS tag가 아닌 문장 자체에 부여됨)
- 문장이나 단어의 시퀀스가 주어졌을 때 얼마나 그럴듯한지(확률)을 결합확률분포를 통해 측정
$P(W) = P(w_{1},w_{2},w_{3}, ..., w_{n})$ - 연관된 task: 뒤에 올 단어의 확률 계산 (조건부확률)
- $P(W)$ 계산: Chain Rules of Probability를 통해 Decompose
$P(w_{1},w_{2},w_{3}, ..., w_{n}) = P(w_{1})P(w_{2}|w_{1})P(w_{3}|w_{1},w_{2})...P(w_{n}|w_{1},...,w_{n-1})$
Applications
- Machine Translation(기계 번역)
e.g.) high wind tonight가 large wind tonight 보다 확률이 높음 - Spell correction (오탈자 교정)
더 확률이 높은 문장으로 교체 - Speech recognition (음성 인식)
e.g.) P(I saw a van) >> (eyes awe of an) 발음은 비슷하나 확률이 다름 - Summarization, question-answering, etc...
Markov Assumption
- $P(w_{n}|w_{1},w_{2},w_{3}, ..., w_{n-1})$에서 n이 커질수록 조건에 해당하는 부분의 계산이 어려워짐
- 조건부 확률을 추정할 때 k개의 이전 단어만 고려
- 가장 단순한 케이스: Unigram model (각 단어가 독립적으로 발생할 때를 가정)
- Bigram model: 이전 단어에만 영향을 받음(조건)을 가정
- N-gram models: trigrams, 4-grams, 5-grams
- 언어 자체가 long-distance dependencies(먼 거리의 의존성)를 가진다면 파악하기 쉽지 않음
- e.g.) Google Books N-gram
Neural Network-based Language Model
(Recurrent Neural Network)RNN-based Language Model
Sequence to Sequence Learning
Performance Improvements
- GPT-2 (Open AI): Too Good to open the source code (?)
요약
- Syntax Analysis (구문 분석)은 형식 문법의 규칙을 따르는 위계구조/형태/문장구조를 분석하는 과정으로 문자열을 Parser를 통해 특정한 문법에 걸맞게 변환한다.
- 구문 분석 또한 어휘적 모호성과 구조적 모호성을 가진다는 어려움이 있다.
- 언어 모델은 문장 자체에 확률을 부여하는 것으로, 기계 번역, 오탈자 교정, 음성 인식, 요약, QA(질의응답) 등에 사용된다.
- 언어 모델은 마르코프 가정을 통한 확률적 언어 모델에서 점차 신경망 기반, RNN이나 Sequence to Sequence 기반 등의 과정으로 발전되었다.
반응형
'딥러닝과 자연어처리 (DL & NLP) > 강의노트 - Text Analytics (고려대 강필성 교수님)' 카테고리의 다른 글
| [강의노트] 05-1 Text Representation II - Distributed Representation Part 1 (NNLM) (1) | 2024.07.10 |
|---|---|
| [강의노트] 04 Text Representation I - Classic Methods (0) | 2024.07.09 |
| [강의노트] 02-2 Text Preprocessing - Part 2 (0) | 2024.06.28 |
| [강의노트] 02-1 Text Preprocessing - Part 1 (0) | 2024.06.27 |
| [강의노트] 01-2 Introduction to Text Analytics - Part 2 (0) | 2024.06.26 |


댓글