네이버 부스트캠프 AI Tech 7기/National Language Processing (NLP)
[NLP] Word Embedding - Word2Vec (CBOW vs Skip-gram)
YS_LEE
2024. 8. 29. 13:37
반응형
Word Embedding
One-Hot Encoding
- 단어를 Categorical variable로 Encoding한 벡터로 표현
- 단어는 하나의 차원이 각각의 단어를 뜻하도록 표현할 수 있음 (다른 모든 차원은 0인 Sparse representation)
- 단어들 간의 내적은 항상 0이며, 유클리드 거리는 항상 $\sqrt2$
Distributed Vector (Dense Vector)
- 원-핫 인코딩의 문제점: 희소 표현(sparse representation)
- 단어의 의미를 다차원 공간에 0이 아닌 값의 형태로 표현(벡터화): 분산 표현(distributed representation)
- 비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다는 분포 가설(distributional hypothesis)을 따름
- 유클리드 거리, 내적, 코사인 유사도는 단어간 의미론적 유사성을 나타냄
Word2Vec
- Word embedding(단어들의 의미적 유사성을 벡터화)의 대표적인 방법론
- 주변 단어들의 정보(확률 분포)들을 이용해 단어 벡터를 표현
- 윈도우(window): 중심 혹은 주변 단어를 예측하기 위해서 앞뒤로 몇 개의 단어를 볼지를 나타내는 범위
- 슬라이딩 윈도우(sliding window): 윈도우를 옆으로 움직여서 주변 단어와 중심 단어의 선택을 변경해가며 학습을 위한 데이터 셋을 만드는 방식
- Skip-gram 방식과 CBoW (Continuous Bag of Words) 방식이 있음
- 단어 벡터는 단어들 간의 관계를 나타냄
vec[queen] - vec[king] = vec[woman] - vec[man] - 워드 벡터들이 유클리드 거리에 따른 의미적 유사성(Semantic Similarity)을 가짐
CBOW
- 주변 단어들로 한 단어를 예측하는 방식
- 임베딩 레이어(Embedding layer)는 일반적인 은닉층과는 달리 활성화 함수가 존재하지 않는 룩업 테이블 연산을 담당하는 층으로 투사층(projection layer) 이라고도 부름
- 동작 원리
- 입력 벡터로 주변 단어들의 원-핫 벡터를 사용한다.
- 임베딩 레이어W (V x M)를 거쳐 저차원 밀집 벡터(dense vector)로 변환한다.
- 각 단어의 임베딩 벡터를 합산하거나 평균을 내어 하나의 벡터로 결합한다.
- 가중치 행렬 W` (M x V)와 곱한 뒤 소프트맥스(softmax) 함수를 통과하여 스코어벡터를 구한다.
- 교차 엔트로피(Cross Entropy) 손실 함수 를 사용하여 중심 단어의 원-핫 벡터와 스코어 벡터 사이의 오차를 줄이기 위해 가중치를 조정한다. (= 역전파를 수행하여 W와 W`를 학습한다.)
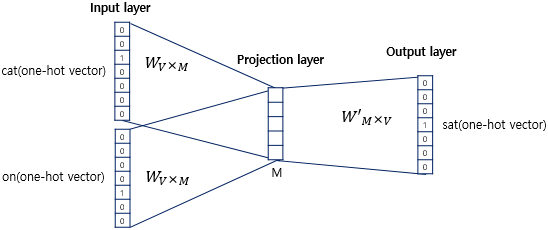
이미지 출처: https://wikidocs.net/22660
Skip-gram
- 한 단어로 주변 단어들을 예측하기 때문에 투사층에서 벡터들의 평균을 구하는 과정이 없다.
- log probability를 최대화 (k번째 단어가 주어졌을 때 k 앞뒤로 주어지는 단어들의 생성확률을 높이는 것)
- 나머지 과정은 CBOW와 동일한데, 특히 Skip-gram 모델에서 출력 측 가중치 W`는 버리고 입력 측 가중치 W만 최종 단어의 분산 표현으로 사용한다.
- 전반적으로 Skip-gram이 CBOW보다 성능이 좋다고 알려져 있다.

Skip-gram와 CBOW 성능 비교
- 직관적으로 생각했을 때 정보를 더 많이 받아 하나의 단어를 예측하는 CBOW가 더 성능이 좋을 것 같아 보이지만 Skip-gram이 더 좋은 성능을 보인다.
- 이는 Gradient flow 관점에서 본다면 CBOW는 하나의 단어에서 주변 단어들의 gradient를 업데이트하는 반면 Skip-gram은 주변 단어들의 정보를 하나의 gradient를 업데이트하는데 사용하기 때문이라고 볼 수 있다.
(이해하기 어렵다면 쉬운 문제만 푼 CBOW 모델보다 어려운 문제를 푼 Skip-gram 모델이 만드는 단어의 분산 표현이 더 뛰어날 것이다 라고 생각할 수 있다.) - 반면 학습 속도 면에서는 CBOW가 훨씬 빠르다.
학습 전략(Learning strategy)
- 모든 주변 단어를 사용하지 말고 각각 하나씩 계산한다.
(Network에서 동시에 계산하나 따로 따로 계산하여 더하나 동일하다) - 훈련해야 할 가중치 크기: 2 x V x N (거대함)
- Word pairs and phrases: 빈번히 나오는 단어 쌍이나 구는 하나의 단어로 취급
- Subsampling frequents words: 너무 많이 나오는 단어나 관사 등을 학습을 적게 시키기
- training examples 개수 줄이기 위함
- The probability of word wiwi, being removed
- Negative sampling: 전체 모든 단어를 가지고 학습하지 말고 샘플링한 몇 개의 단어만 사용하여 가중치 업데이트
참고자료
딥 러닝을 이용한 자연어 처리 입문
밑바닥부터 시작하는 딥러닝 2
Text Analytics (고려대 강필성 교수님)
반응형